

When CERN’s LHC collider begins operation, it will be the most powerful machine of its type in the world, providing research facilities for thousands of researchers from all over the globe.
The computing capacity required for analysing the data generated by these big LHC experiments will be several orders of magnitude greater than that used by current experiments at CERN, itself already substantial. Satisfying this vast data-processing appetite will require the integrated use of computing facilities installed at several research centres across Europe, the US and Asia.
During the last two years the Models of Networked Analysis at Regional Centres for LHC Experiments (MONARC) project, supported by a number of institutes participating in the LHC programme, has been developing and evaluating models for LHC computing. MONARC has also developed tools for simulating the behaviour of such models when implemented in a wide-area distributed computing environment. This requirement arrived on the scene at the same time as a growing awareness that major new projects in science and technology need matching computer support and access to resources worldwide.
In the 1970s and 1980s the Internet grew up as a network of computer networks, each established to service specific communities and each with a heavy commitment to data processing.
In the late 1980s the World Wide Web was invented at CERN to enable particle physicists scattered all over the globe to access information and participate actively in their research projects directly from their home institutes. The amazing synergy of the Internet, the boom in personal computing and the growth of the Web grips the whole world in today’s dot.com lifestyle.
Internet, Web, what next?
However, the Web is not the end of the line. New thinking for the millennium, summarized in a milestone book entitled The Grid by Ian Foster of Argonne and Carl Kesselman of the Information Sciences Institute of the University of Southern California, aims to develop new software (“middleware”) to handle computations spanning widely distributed computational and information resources – from supercomputers to individual PCs.
Just as a grid for electric power supply brings watts to the wallplug in a way that is completely transparent to the end user, so the new data Grid will do the same for information.
Each of the major LHC experiments – ATLAS, CMS and ALICE – is estimated to require computer power equivalent to 40,000 of today’s PCs. Adding LHCb to the equation gives a total equivalent of 140,000 PCs, and this is only for day 1 of the LHC.
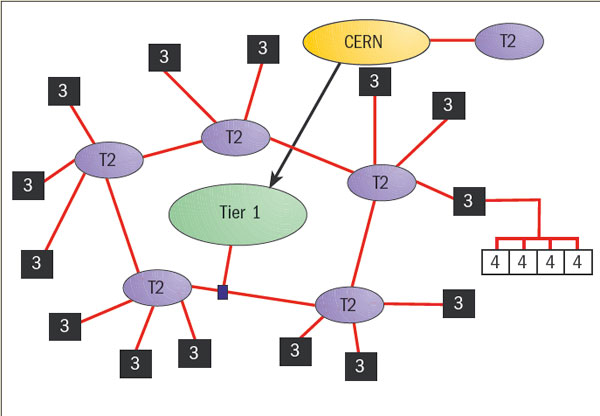
Within about a year this demand will have grown by 30%. The demand for data storage is equally impressive, calling for some several thousand terabytes – more information than is contained in the combined telephone directories for the populations of millions of planets. With users across the globe, this represents a new challenge in distributed computing. For the LHC, each experiment will have its own central computer and data storage facilities at CERN, but these have to be integrated with regional computing centres accessed by the researchers from their home institutes.
CERN serves as Grid testbed
As a milestone en route to this panorama, an interim solution is being developed, with a central facility at CERN complemented by five or six regional centres and several smaller ones, so that computing can ultimately be carried out on a cluster in the user’s research department. To see whether this proposed model is on the right track, a testbed is to be implemented using realistic data.
Several nations have launched new Grid-oriented initiatives – in the US by NASA and the National Science Foundation, while in Europe particle physics provides a natural focus for work in, among others, the UK, France, Italy and Holland. Other areas of science, such as Earth observation and bioinformatics, are also on board. In Europe, European Commission funding is being sought to underwrite this major effort to propel computing into a new orbit.




