

The design and deployment of a completely new computing model – the O2 project – allows the ALICE collaboration to merge online and offline data processing into a single software framework to cope with the demands of Run 3 and beyond. Volker Lindenstruth goes behind the scenes.

The Large Hadron Collider (LHC) roared back to life on 5 July 2022, when proton–proton collisions at a record centre-of-mass energy of 13.6 TeV resumed for Run 3. To enable the ALICE collaboration to benefit from the increased instantaneous luminosity of this and future LHC runs, the ALICE experiment underwent a major upgrade during Long Shutdown 2 (2019–2022) that will substantially improve track reconstruction in terms of spatial precision and tracking efficiency, in particular for low-momentum particles. The upgrade will also enable an increased interaction rate of up to 50 kHz for lead–lead (PbPb) collisions in continuous readout mode, which will allow ALICE to collect a data sample more than 10 times larger than the combined Run 1 and Run 2 samples.
ALICE is a unique experiment at the LHC devoted to the study of extreme nuclear matter. It comprises a central barrel (the largest data producer) and a forward muon “arm”. The central barrel relies mainly on four subdetectors for particle tracking: the new inner tracking system (ITS), which is a seven-layer, 12.5 gigapixel monolithic silicon tracker (CERN Courier July/August 2021 p29); an upgraded time projection chamber (TPC) with GEM-based readout for continuous operation; a transition radiation detector; and a time-of-flight detector. The muon arm is composed of three tracking devices: a newly installed muon forward tracker (a silicon tracker based on monolithic active pixel sensors), revamped muon chambers and a muon identifier.
Due to the increased data volume in the upgraded ALICE detector, storing all the raw data produced during Run 3 is impossible. One of the major ALICE upgrades in preparation for the latest run was therefore the design and deployment of a completely new computing model: the O2 project, which merges online (synchronous) and offline (asynchronous) data processing into a single software framework. In addition to an upgrade of the experiment’s computing farms for data readout and processing, this necessitates efficient online compression and the use of graphics processing units (GPUs) to speed up processing.
Pioneering parallelism
As their name implies, GPUs were originally designed to accelerate computer-graphics rendering, especially in 3D gaming. While they continue to be utilised for such workloads, GPUs have become general-purpose vector processors for use in a variety of settings. Their intrinsic ability to perform several tasks simultaneously gives them a much higher compute throughput than traditional CPUs and enables them to be optimised for data processing rather than, say, data caching. GPUs thus reduce the cost and energy consumption of associated computing farms: without them, about eight times as many servers of the same type and other resources would be required to handle the ALICE TPC online processing of PbPb collision data at a 50 kHz interaction rate.
Since 2010, when the high-level trigger online computer farm (HLT) entered operation, the ALICE detector has pioneered the use of GPUs for data compression and processing in high-energy physics. The HLT had direct access to the detector readout hardware and was crucial to compress data obtained from heavy-ion collisions. In addition, the HLT software framework was advanced enough to perform online data reconstruction. The experience gained during its operation in LHC Run 1 and 2 was essential for the design and development of the current O2 software and hardware systems.
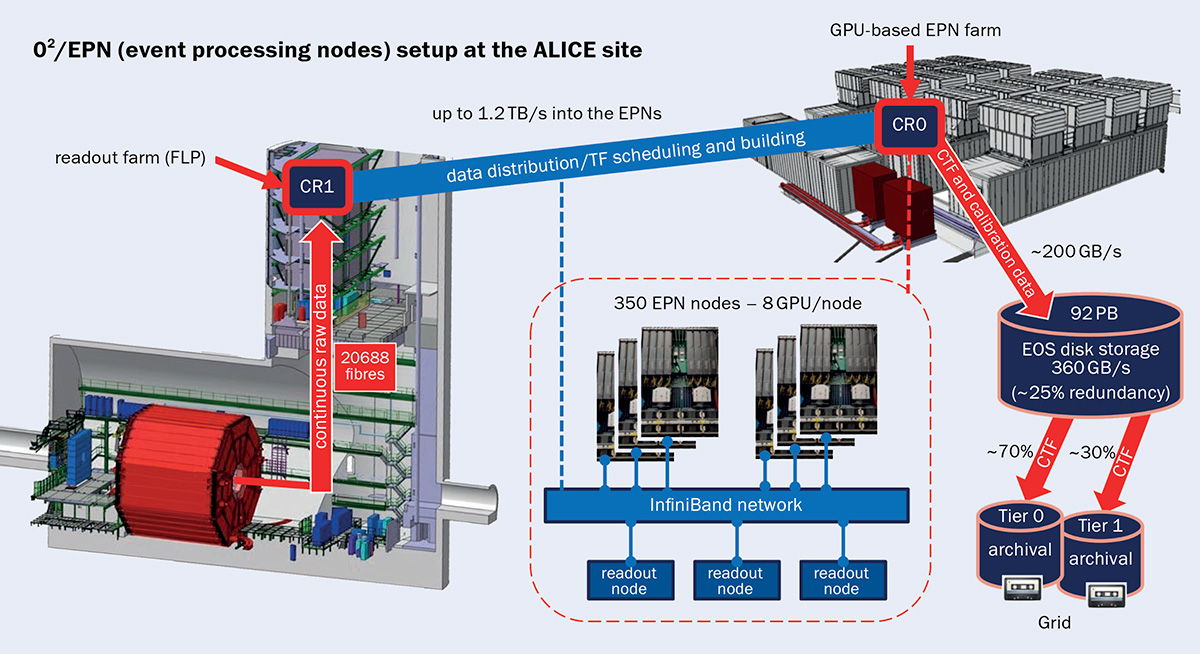
For data readout and processing during Run 3, the ALICE detector front-end electronics are connected via radiation-tolerant gigabit-transceiver links to custom field programmable gate arrays (see “Data flow” figure). The latter, hosted in the first-level processor (FLP) farm nodes, perform continuous readout and zero-suppression (the removal of data without physics signal). In the case of the ALICE TPC, zero-suppression reduces the data rate from a prohibitive 3.3 TB/s at the front end to 900 GB/s for 50 kHz minimum-bias PbPb operations. This data stream is then pushed by the FLP readout farm to the event processing nodes (EPN) using data-distribution software running on both farms.
Located in three containers on the surface close to the ALICE site, the EPN farm currently comprises 350 servers, each equipped with eight AMD GPUs with 32 GB of RAM each, two 32-core AMD CPUs and 512 GB of memory. The EPN farm is optimised for the fastest possible TPC track reconstruction, which constitutes the bulk of the synchronous processing, and provides most of its computing power in the form of GPU processing. As data flow from the front end into the farms and cannot be buffered, the EPN computing capacity must be sufficient for the highest data rates expected during Run 3.
Having pioneered the use of GPUs in high-energy physics for more than a decade, ALICE now employs GPUs heavily to speed up online and offline processing
Due to the continuous readout approach at the ALICE experiment, processing does not occur on a particular “event” triggered by some characteristic pattern in detector signals. Instead, all data is read out and stored during a predefined time slot in a time frame (TF) data structure. The TF length is usually chosen as a multiple of one LHC orbit (corresponding to about 90 microseconds). However, since a whole TF must always fit into the GPU’s memory, the collaboration chose to use 32 GB GPU memory to grant enough flexibility in operating with different TF lengths. In addition, an optimisation effort was put in place to reuse GPU memory in consecutive processing steps. During the proton run in 2022 the system was stressed by increasing the proton collision rates beyond those needed in order to maximise the integrated luminosity for physics analyses. In this scenario the TF length was chosen to be 128 LHC orbits. Such high-rate tests aimed to reproduce occupancies similar to the expected rates of PbPb collisions. The experience of ALICE demonstrated that the EPN processing could sustain rates nearly twice the nominal design value (600 GB/s) originally foreseen for PbPb collisions. Using high-rate proton collisions at 2.6 MHz the readout reached 1.24 TB/s, which was fully absorbed and processed on the EPNs. However, due to fluctuations in centrality and luminosity, the number of TPC hits (and thus the required memory size) varies to a small extent, demanding a certain safety margin.
Flexible compression
At the incoming raw-data rates during Run 3, it is impossible to store the data – even temporarily. Hence, the outgoing data is compressed in real time to a manageable size on the EPN farm. During this network transfer, event building is carried out by the data distribution suite, which collects all the partial TFs sent by the detectors and schedules the building of the complete TF. At the end of the transfer, each EPN node receives and then processes a full TF containing data from all ALICE detectors.

The detector generating by far the largest data volume is the TPC, contributing more than 90% to the total data size. The EPN farm compresses this to a manageable rate of around 100 GB/s (depending on the interaction rate), which is then stored to the disk buffer. The TPC compression is particularly elaborate, employing several steps including a track-model compression to reduce the cluster entropy before the entropy encoding. Evaluating the TPC space-charge distortion during data taking is also the most computing-intensive aspect of online calibrations, requiring global track reconstruction for several detectors. At the increased Run 3 interaction rate, processing on the order of one percent of the events is sufficient for the calibration.
During data taking, the EPN system operates synchronously and the TPC reconstruction fully loads the GPUs. With the EPN farm providing 90% of its compute performance via GPUs, it is also desirable to maximise the GPU utilisation in the asynchronous phase. Since the relative contribution of the TPC processing to the overall workload is much smaller in the asynchronous phase, GPU idle times would be high and processing would be CPU-limited if the TPC part only ran on the GPUs. To use the GPUs maximally, the central-barrel asynchronous reconstruction software is being implemented with native GPU support. Currently, around 60% of the workload can run on a GPU, yielding a speedup factor of about 2.25 compared to CPU-only processing. With the full adaptation of the central-barrel tracking software to the GPU, it is estimated that 80% of the reconstruction workload could be processed on GPUs.
In contrast to synchronous processing, asynchronous processing includes the reconstruction of data from all detectors, and all events instead of only a subset; physics analysis-ready objects produced from asynchronous processing are then made available on the computing Grid. As a result, the processing workload for all detectors, except the TPC, is significantly higher in the asynchronous phase. For the TPC, clustering and data compression are not necessary during asynchronous processing, while the tracking runs on a smaller input data set because some of the detector hits were removed during data compression. Consequently, TPC processing is faster in the asynchronous phase than in the synchronous phase. Overall, the TPC contributes significantly to asynchronous processing, but is not dominant. The asynchronous reconstruction will be divided between the EPN farm and the Grid sites. While the final distribution scheme is still to be decided, the plan is to split reconstruction between the online computing farm, the Tier 0 and the Tier 1 sites. During the LHC shutdown periods, the EPN farm nodes will almost entirely be used for asynchronous processing.
Great shape
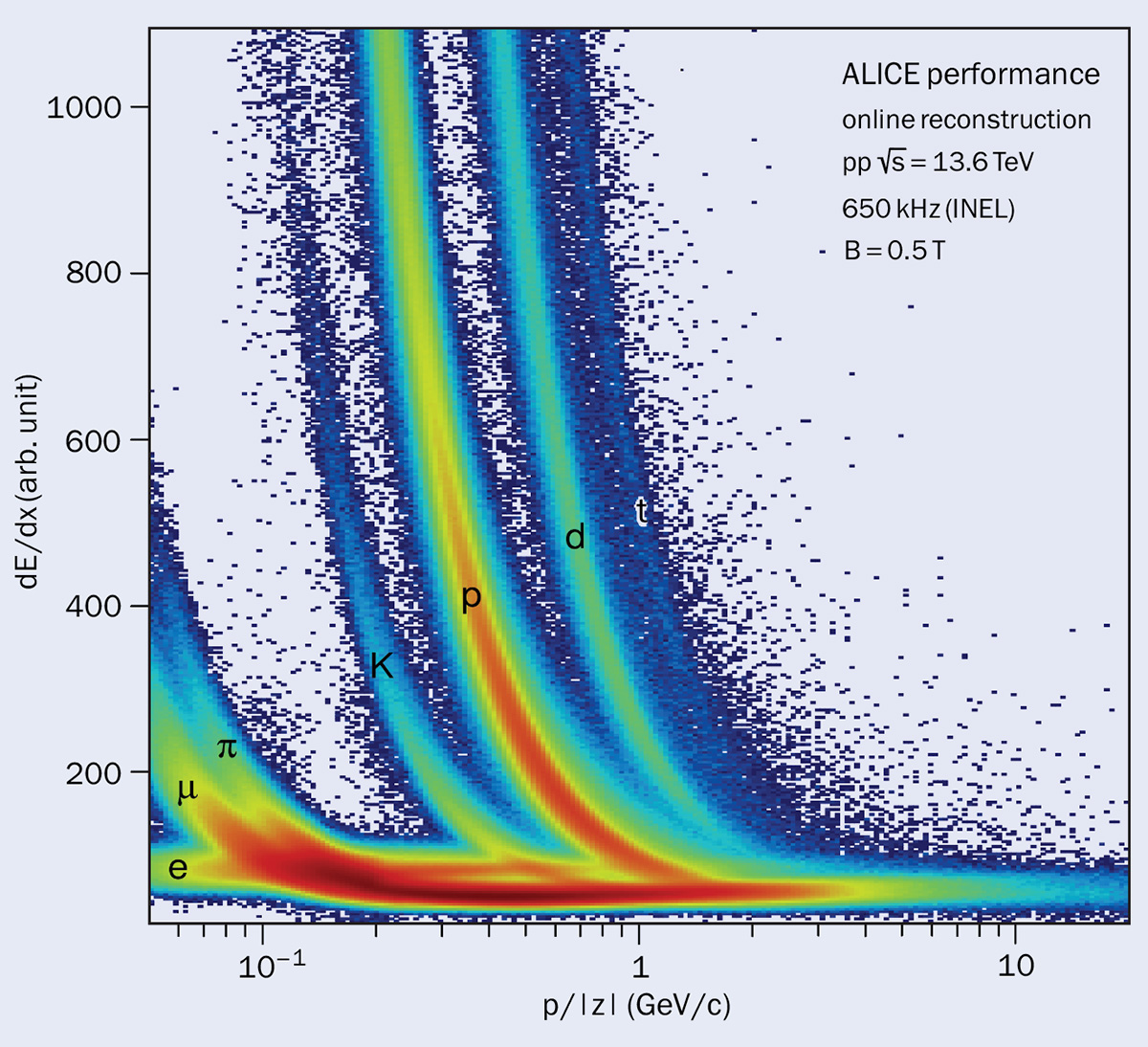
In 2021, during the first pilot-beam collisions at injection energy, synchronous processing was running and successfully commissioned. In 2022 it was used during nominal LHC operations, where ALICE performed online processing of pp collisions at a 2.6 MHz inelastic interaction rate. At lower interaction rates (both for pp and PbPb collisions), ALICE ran additional processing tasks on free EPN resources, for instance online TPC charged-particle energy-loss determination, which would not be possible at the full 50 kHz PbPb collision rate. The particle-identification performance is demonstrated in the figure “Particle ID”, in which no additional selections on the tracks or detector calibrations were applied.
Another performance metric used to assess the quality of the online TPC reconstruction is the charged-particle tracking efficiency. The efficiency for reconstructing tracks from PbPb collisions at a centre-of-mass energy of 5.52 TeV per nucleon pair ranges from 94–100% for pT > 0.1 GeV/c. Here the fake-track rate is rather negligible, however the clone rate increases significantly for low-pT primary tracks due to incomplete track merging of very low-momentum particles that curl in the ALICE solenoidal field and leave and enter the TPC multiple times.
The effective use of GPU resources provides extremely efficient processors. Additionally, GPUs deliver improved data quality and compute cost and efficiency – aspects that have not been overlooked by the other LHC experiments. To manage their data rates in real time, LHCb developed the Allen project, a first-level trigger processed entirely on GPUs that reduces the data rate prior to the alignment, calibration and final reconstruction steps by a factor of 30–60. With this approach, 4 TB/s are processed in real time, with 10 GB of the most interesting collisions selected for physics analysis.
At the beginning of Run 3, the CMS collaboration deployed a new HLT farm comprising 400 CPUs and 400 GPUs. With respect to a traditional solution using only CPUs, this configuration reduced the processing time of the high-level trigger by 40%, improved the data-processing throughput by 80% and reduced the power consumption of the farm by 30%. ATLAS uses GPUs extensively for physics analyses, especially for machine-learning applications. Focus has also been placed on data processing, anticipating that in the following years much of that can be offloaded to GPUs. For all four LHC experiments, the future use of GPUs is crucial to reduce the cost, size and power consumption within the higher luminosities of the LHC.
Having pioneered the use of GPUs in high-energy physics for more than a decade, ALICE now employs GPUs heavily to speed up online and offline processing. Today, 99% of synchronous processing is performed on GPUs, dominated by the largest contributor, the TPC.
More code
On the other hand, only about 60% of asynchronous processing (for 650 kHz pp collisions) is currently running on GPUs, i.e. offline data processing on the EPN farm. For asynchronous processing, even if the TPC is still an important contributor to the compute load, there are several other subdetectors that are important. In fact, there is an ongoing effort to port considerably more code to the GPUs. Such an effort will increase the fraction of GPU-accelerated code to beyond 80% for full barrel tracking. Eventually ALICE aims to run 90% of the whole asynchronous processing on GPUs.
In November 2022 the upgraded ALICE detectors and central systems saw PbPb collisions for the first time during a two-day pilot run at a collision rate of about 50 Hz. High-rate PbPb processing was validated by injecting Monte Carlo data into the readout farm and running the whole data processing chain on 230 EPN nodes. Due to the TPC data volumes being somewhat larger than initially expected, this stress test is now being revalidated with continuously optimised TPC firmware using 350 EPN nodes together with the final TPC firmware to provide the required 20% compute margin with respect to foreseen 50 kHz PbPb operations in October 2023. Together with the upgraded detector components, the ALICE experiment has never been in better shape to probe extreme nuclear matter during the current and future LHC runs.
Further reading
ALICE Collab. 2023 arXiv:2302.01238.
ALICE Collab. 2019 Comput. Phys. Commun. 242 25.
ALICE Collab. 2015 CERN-LHCC-2015-006.






{kind=link}