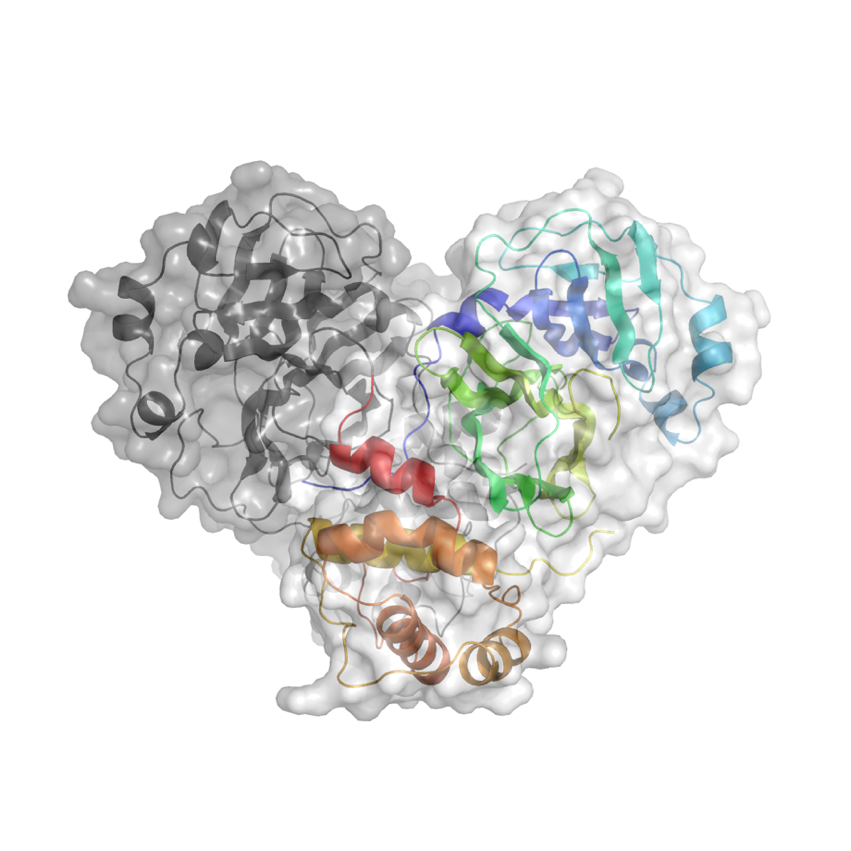
LHCb will soon become the first LHC experiment able to run simultaneously with two separate interaction regions. As part of the ongoing major upgrade of the LHCb detector, the new SMOG2 fixed‑target system will be installed in long shutdown 2. SMOG2 will replace the previous System for Measuring the Overlap with Gas (SMOG), which injected noble gases into the vacuum vessel of LHCb’s vertex detector (VELO) at a low rate with the initial goal of calibrating luminosity measurements. The new system has several advantages, including the ability to reach effective area densities (and thus luminosities) up to two orders of magnitude higher for the same injected gas flux.
SMOG2 is a gas target confined within a 20 cm‑long aluminium storage cell that is mounted at the upstream edge of the VELO, 30 cm from the main interaction point, and coaxial with the LHC beam (figure 1). The storage‑cell technology allows a very limited amount of gas to be injected in a well defined volume within the LHC beam pipe, keeping the gas pressure and density profile under precise control, and ensuring that the beam‑pipe vacuum level stays at least two orders of magnitude below the upper threshold set by the LHC. With beam‑gas interactions occurring at roughly 4% of the proton–proton collision rate at LHCb, the lifetime of the beam will be essentially unaffected. The cell is made of two halves, attached to the VELO with an alignment precision of 200 μm. Like the VELO halves, they can be opened for safety during LHC beam injection and tuning, and closed for data‑taking. The cell is sufficiently narrow that as small a flow as 10–15 particles per second will yield tens of pb–1 of data per year. The new injection system will be able to switch between gases within a few minutes, and in principle is capable of injecting not just noble gases, from helium up to krypton and xenon, but also several other species, including H2, D2, N2, and O2.
SMOG2 will open a new window on QCD studies and astroparticle physics at the LHC
SMOG2 will open a new window on QCD studies and astroparticle physics at the LHC, performing precision measurements in poorly known kinematic regions. Collisions with the gas target will occur at a nucleon–nucleon centre‑of‑mass energy of 115 GeV for a proton beam of 7 TeV, and 72 GeV for a Pb beam of 2.76 TeV per nucleon. Due to the boost of the interacting system in the laboratory frame and the forward geometrical acceptance of LHCb, it will be possible to access the largely unexplored high‑x and intermediate Q2 regions.
Combined with LHCb’s excellent particle identification capabilities and momentum resolution, the new gas target system will allow us to advance our understanding of the gluon, antiquark, and heavy‑quark components of nucleons and nuclei at large‑x. This will benefit searches for physics beyond the Standard Model at the LHC, by improving our knowledge of the parton distribution functions of both protons and nuclei, particularly at high‑x, where new particles are most often expected, and will inform the physics programmes of proposed next‑generation accelerators such as the Future Circular Collider. The gas target will also allow the dynamics and spin distributions of quarks and gluons inside unpolarised nucleons to be studied for the first time at the LHC, a decade before corresponding measurements at much higher accuracy are performed at the Electron‑Ion Collider in the US. Studying particles produced in collisions with light nuclei, such as He, and possibly N and O, will also allow LHCb to give important inputs to cosmic‑ray physics and dark‑matter searches. Last but not least, SMOG2 will allow LHCb to perform studies of heavy‑ion collisions at large rapidities, in an unexplored energy range between the SPS and RHIC, offering new insights into the QCD phase diagram.
As part of the global response to the COVID-19 pandemic, a team led by physicists and engineers from the LHCb collaboration has proposed a design for a novel ventilator. The High Energy Ventilator (HEV) is based on components which are simple and cheap to source, complies with hospital standards, and supports the most requested ventilator-operation modes, writes the newly formed HEV collaboration. Though the system needs to be verified by medical experts before it can enter use, in the interests of rapid development the HEV team has presented the design to generate feedback, corrections and support as the project progresses. The proposal is one of several recent and rapidly developing efforts launched by high-energy physicists to help combat COVID-19.
The majority of people who contract COVID-19 suffer mild symptoms, but in some cases the disease can cause severe breathing difficulties and pneumonia. For such patients, the availability of ventilators that deliver oxygen to the lungs while removing carbon dioxide could be the difference between life and death. Even with existing ventilator suppliers ramping up production, the rapid rise in COVID-19 infections is causing a global shortage of devices. Multiple efforts are therefore being mounted by governments, industry and academia to meet the demand, with firms which normally operate in completely different sectors – such as Dyson and General Motors – diverting resources to the task.
There are many proposals on the market, but we don’t know now which ones will in the end make a difference, so everything which could be viable should be pursued
Paula Collins
HEV was born out of discussions in the LHCb VELO group, when lead-designer Jan Buytaert (CERN) realised that the systems which are routinely used to supply and control gas at desired temperatures and pressures in particle-physics detectors are well matched to the techniques required to build and operate a ventilator. The team started from a set of guidelines recently drawn up by the UK government’s Medicines and Healthcare products Regulatory Agency regarding rapidly manufactured ventilator systems, and was encouraged by a 3D-printed prototype constructed at the University of Liverpool in response to these guidelines. The driving pressure of ventilators — which must be able to handle situations of rapidly changing lung compliance, and potential collapse and consolidation — is a crucial factor for patient outcomes. The HEV team therefore aimed to produce a patient-safety-first design with a gentle and precise pressure control that is responsive to the needs of the patient, and which offers internationally recommended operation modes.
As the HEV team comprises physicists, not medics, explains HEV collaborator Paula Collins of CERN, it was vital to get the relevant input from the very start. “Here we have benefitted enormously from the experience and knowledge of CERN’s HSE [occupational health & safety and environmental protection] group for medical advice, conformity with applicable legislation and health-and-safety requirements, and the working relationship with local hospitals. The team is also greatly supported from other CERN departments, in particular for electronic design and the selection of the best components for gas manipulation. During lockdown, the world is turning to remote connection, and we were very encouraged to find that it was possible in a short space of time to set up an online chat group of experienced anesthesiologists and respiratory experts from Australia, Belgium, Switzerland and Germany, which sped up the design considerably.”
Stripped-down approach The HEV concept relies on easy-to-source components, which include electro-valves, a two-litre buffer container, a pressure regulator and several pressure sensors. Embedded components — currently Arduino and Rasbperry Pi — are being used to address portability requirements. The unit’s functionality will be comprehensive enough to provide long-term support to patients in the initial or recovery phases, or with more mild symptoms, freeing up high-end machines for the most serious intensive care, explains Collins: “It will incorporate touchscreen control intuitive to use for qualified medical personnel, even if they are not specialists in ventilator use, and it will include extensive monitoring and failsafe mechanisms based on CERN’s long experience in this area, with online training to be developed.”
The first stage of prototyping, which was achieved at CERN on 27 March, was to demonstrate that the HEV working principle is sound and allows the ventilator to operate within the required ranges of pressure and time. The desired physical characteristics of the pressure regulators, valves and pressure sensors are now being refined, and the support of clinicians and international organisations is being harnessed for further prototyping and deployment stages. “This is a device which has patient safety as a major priority,” says HEV collaborator Themis Bowcock of the University of Liverpool. “It is aimed at deployment round the world, also in places that do not necessarily have state-of-the-art facilities.”
Complementary designs The HEV concept complements another recent ventilator proposal, initiated by physicists in the Global Argon Dark Matter Collaboration. The Mechanical Ventilator Milano (MVM) is optimised to permit large-scale production in a short amount of time and at a limited cost, also relying on off-the-shelf components that are readily available. In contrast to the HEV design, which aims to control pressure by alternately filling and emptying a buffer, the MVM project regulates the flow of the incoming mixture of oxygen and air via electrically controlled valves. The proposal stems from a cooperation of particle- and nuclear-physics laboratories and universities in Canada, Italy and the US, with an initial goal to produce up to 1000 units in each of the three countries while the interim certification process is ongoing. Clinical requirements are being developed with medical experts, and detailed testing and qualification of the first prototype is presently underway with a breathing simulator at Ospedale San Gerardo in Monza, Italy.
Sharing several common ideas with the MVM principle, but with emphasis on further reducing the number and specificity of components to make construction possible during times of logistical disruption, a team led by particle physicists at the Laboratory of Instrumentation and Experimental Particles Physics in Portugal has also posted a proof-of-concept study for a ventilator on arXiv. All ventilator designs are evolving quickly and require further development before they can be deployed in hospitals.
“It is difficult to conceive a project which goes all the way and includes all the bells and whistles needed to get it into the hospital, but this is our firm goal,” says Collins. “After one week we had a functioning demonstrator, after two weeks we aim to test on a medical mechanical lung and to start prototyping in the hospital context. We find ourselves in a unique and urgent situation where there are many proposals on the market, but we don’t know now which ones will in the end make a difference, so everything which could be viable should be pursued.”
At a time when many countries are locking down borders, limiting public gatherings, and encouraging isolation, the Diamond Light Source in Oxfordshire, UK, has been ramping up its intensity, albeit in an organised and controlled manner. The reason: these scientists are working tirelessly on drug-discovery efforts to quell COVID-19.
It is a story that requires fast detectors, reliable robotics and powerful computing infrastructures, artificial intelligence, and one of the brightest X-ray sources in the world. And it is made possible by international collaboration, dedication, determination and perseverance.
Synchrotron light sources are particle accelerators capable of producing incredibly bright X-rays, by forcing relativistic electrons to accelerate on curved trajectories. Around 50 facilities exist worldwide, enabling studies over a vast range of topics. Fanning out tangentially from Diamond’s 562-m circumference storage ring are more than 30 beamlines equipped with instrumentation to serve a multitude of user experiments. The intensely bright X-rays (corresponding to flux of around 9 × 1012 photons per second) are necessary for determining the atomic structure of proteins, including the proteins which make up viruses. As such, synchrotron light sources around the world are interrupting their usual operations to work on mapping the structure of the SARS-CoV-2 virus.
Knowing the atomic structure of the virus is like knowing how the enemy thinks
Knowing the atomic structure of the virus is like knowing how the enemy thinks. A 3D visualisation of the building blocks of the structure at an atomic level would allow scientists to understand how the virus functions. Enzymes, the molecular machines that allow the virus to replicate, are key to this process. Scientists at Diamond are exploring the binding site of the main SARS-CoV-2 protease. A drug that binds to this enzyme’s active site would throw a chemical spanner in the works, blocking the virus’ ability to replicate and limiting the spread of the disease.
By way of reminder: Coronavirus is the family of viruses responsible for the common cold, MERS, SARS, etc. Novel coronavirus, aka SARS-CoV-2, is the newly discovered type of coronavirus, and COVID-19 is the disease which it causes.
Call to arms
On 26 January, Diamond’s life-sciences director, Dave Stuart, received a phone call from structural biologist Zihe Rao of ShanghaiTech University in China. Rao, along with his colleague Haitao Yang, had solved the structure of the main SARS-CoV-2 protease with a covalent inhibitor using the Shanghai Synchrotron Radiation Facility (SSRF) in China. Furthermore, they had made the solution freely and publicly available on the worldwide Protein Data Bank.
During the phone call, Rao informed Stuart that their work had been halted by a scheduled shutdown of the SSRF. The Diamond team rapidly mobilised. Since shipping biological samples from Shanghai at the height of the coronavirus in China was expected to be problematic, the team at Diamond ordered the synthetic gene. A synthetic gene can be generated provided the ordering of T, A, C and G nucleotides in the DNA sequence is known. That synthetic gene can be genetically engineered into a bacterium, in this case Escherichia. coli, which reads the sequence and generates the coronavirus protease in large enough quantities for the researchers at Diamond to determine its structure and screen for potential inhibitors.
Eleven days later on 10 February, the synthetic gene arrived. At this point, Martin Walsh, Diamond’s deputy director of life sciences, and his team (consisting of Claire Strain-Damerell, Petra Lukacik, and David Owen) dropped everything. With the gene in hand, the group immediately set up experimental trials to try to generate protein crystals. In order to determine the atomic structure, they needed a crystal containing millions of proteins in an ordered grid-like structure.
X-ray radiation bright enough for the rapid analysis of protein structures can only be produced by a synchrotron light source. The X-rays are directed and focused down a beamline onto a crystal and, as they pass through it, they diffract. From the diffraction pattern, researchers can work backwards to determine the 3D electron density maps and the structure of the protein. The result is a complex curled ribbon-like structure with an intricate mess of twists and turns of the protein chain.
The Diamond team set up numerous trials trying to find the optimum conditions for crystallization of the SARS-CoV-2 protease to occur. They modified the pH, the precipitating compounds, chemical composition, protein to solution ratio… every parameter they could vary, they did. Every day they would produce a few thousand trials, of which only a few hundred would produce crystals, and even fewer would produce crystals of sufficient quality. Within a few days of receiving the gene, the first crystals were being produced. They were paltry and thin crystals but large enough to be tested on one of Diamond’s macromolecular crystallography beamlines.
Watching the results come through, Diamond postdoc David Owen described it as the first moment of intense excitement. With crystals that appeared to be “flat like a car wind shield,” he was dubious as to whether they would diffract at all. Nevertheless, the team placed the crystals in the beamline with a resignation that quickly turned into intense curiosity as the results started appearing before them. At that moment Owen remembers his doubts fading, as he thought, “this might just work!” And work it did. In fact, Owen recalls, “they diffracted beautifully.” These first diffraction patterns of the SARS-CoV-2 virus were recorded with a resolution of 1.9 Angstrom (1.9 × 10−10 m) — high enough resolution to see the position of all of the chemical groups that allow the protease to do its work.
By 19 February, through constant adjustments and learning, the team knew they could grow good-quality crystals quickly. It was time to bring in more colleagues. The XChem team at Diamond joined the mission to set up fragment-based screening – whereby a vast library of small molecules (“fragments”) are soaked into crystals of the viral protease. These fragments are significantly smaller and functionally simpler than most drug molecules and are a powerful approach to selecting candidates for early drug discovery. By 26 February, 600 crystals had been mounted and the first fragment screen launched. In parallel, the team had been making a series of sample to send to company in Oxford called Exscientia, which has set up an AI platform designed to expediate candidates in drug discovery.
Drug-discovery potential
As of early March, 1500 crystals and fragments have been analysed. Owen attributes the team’s success so far to the incredible amounts of data they could collect and analyse quickly. With huge numbers of data sets, they could pin down the parameters of the viral protease with a high degree of confidence. And with the synchrotron light source they were able to create and analyse the diffraction patterns rapidly. The same amount of data collected with a lab-based X-ray source would have taken approximately 10 years. At Diamond, they were able to collect the data in a few days of accumulated beamtime.
Synchrotron light sources all over the world have been granting priority and rapid access to researchers to support their efforts in discovering more about the virus. Researchers at the Advanced Photon Source in Argonne, US, and at Elettra Sincrotrone in Trieste, Italy are also trying to identify molecules effective against COVID-19, in an attempt to bring us closer to an effective vaccine or treatment. This week, the ESRF in Grenoble, France, announced that it will make its cryo-electron microscope facility available for use. The community has a platform called www.lightsources.org offering an overview of access and calls for proposals.
Synchrotron light sources all over the world have been granting priority and rapid access
In addition to allowing the structure of tens of thousands of biological structures to be elucidated – such as that of the ribosome, which was recognised by the 2009 Nobel Prize in Chemistry — light sources have a strong pedigree in elucidating the structure of viruses. Development of common anti-viral medication that blocks the actions of virus in the body, such as Tamiflu or Relenza, also relied upon synchrotrons to reveal their atomic structure.
Mapping the SARS-CoV-2 protease structures bound to small chemical fragments, the Diamond team demonstrated a crystallography- and fragmentation-screen tour de force. The resulting and ongoing work is a crucial first step in developing a drug. Forgoing the usual academic root of peer-review, the Diamond team have made all of their results openly and freely available to help inform public heath response, limit the spread of the virus with the hope that this can fast-track effective treatment options.
A quadrupole magnet for the high-luminosity LHC (HL-LHC) has been tested successfully in the US, attaining a conductor peak field of 11.4 T – a record for a focusing magnet ready for installation in an accelerator. The 4.2 m-long, 150-mm-single-aperture device is based on the superconductor niobium tin (Nb3Sn) and is one of several quadrupoles being built by US labs and CERN for the HL-LHC, where they will squeeze the proton beams more tightly within the ATLAS and CMS experiments to produce a higher luminosity. The result follows successful tests carried out last year at CERN of the first accelerator-ready Nb3Sn dipole magnet, and both of these milestones are soon to be followed by tests of other 7.2 m and 4.2 m quadrupole magnets at CERN and the US.
“This copious harvest comes after significant recent R&D on niobium-tin superconducting magnet technology and is the best answer to the question if HL-LHC is on time: it is,” says HL-LHC project leader Lucio Rossi of CERN. “We should also underline that this full-length, accelerator-ready magnet performance record is a real textbook case for international collaboration in the accelerator domain: since the very beginning the three US labs and CERN teamed up and managed to have a common and very synergic R&D, particularly for the quadrupole magnet that is the cornerstone of the upgrade. This has resulted in substantial savings and improved output.”
This is a real textbook case for international collaboration in the accelerator domain
Lucio Rossi
The current LHC magnets, which have been tested to a bore field of 8.3 T and are currently operated at 7.7 T at 1.9 K for 6.5 TeV operation, are made from the superconductor niobium-titanium (Nb-Ti). As the transport properties of Nb-Ti are limited for fields beyond 10-11 T at 1.9 K, HL-LHC magnets call for a move to Nb3Sn, which remain superconducting for much higher fields. Although Nb3Sn has been studied for decades and is already in widespread use in solenoids for NMR — not to mention underpinning the large coils, presently being manufactured, that will be used to contain and control the plasma in the ITER fusion experiment – it is more challenging than Nb-Ti to work with: once formed, the Nb3Sn compound becomes brittle and strain sensitive and therefore much harder than niobium-titanium alloy to process into cables to be wound with the accuracy required to achieve the performance and field quality of state-of-the-art accelerator magnets.
Researchers at Fermilab, Brookhaven National Laboratory and Lawrence Berkeley National Laboratory are to provide a total of 16 quadrupole magnets for the interactions regions of the HL-LHC, which is due to operate from 2027. The purpose of a quadrupole magnet is to produce a field gradient in the radial direction with respect to the beam, allowing charged-particle beams to be focused. A test was carried out at Brookhaven in January, when the team operated the 8-tonne quadrupole magnet continuously at a nominal field gradient of around 130 T/m and a temperature of 1.9 K for five hours. Eight longer quadrupole magnets (each providing an equivalent “cold mass” as two US quadrupole magnets) are being produced by CERN.
It’s a very cutting-edge magnet
Kathleen Amm
“We’ve demonstrated that this first quadrupole magnet behaves successfully and according to design, based on the multiyear development effort made possible by DOE investments in this new technology,” said Fermilab’s Giorgio Apollinari, head of the US Accelerator Upgrade Project in a Fermilab press release. “It’s a very cutting-edge magnet,” added Kathleen Amm, who is Brookhaven’s representative for the project.
Dipole tests at CERN
In addition to stronger focusing magnets, the HL-LHC requires new dipole magnets positioned on either side of a collimator to correct off-momentum protons in the high-intensity beam. To gain the required space in the magnetic lattice, Nb3Sn dipole magnets of shorter length and higher field than the current LHC dipole magnets are needed. In July 2019 the CERN magnet group successfully tested a full-length, 5.3-m, 60-mm-twin-aperture dipole magnet – the longest Nb3Sn magnet tested so far – and achieved a nominal bore field of 11.2 T at 1.9 K (corresponding to a conductor peak field of 11.8 T).
“This multi-year effort on Nb3Sn, which we are running together with the US, and our partner laboratories in Europe, is leading to a major breakthrough in accelerator magnet technology, from which CERN, and the whole particle physics community, will profit for the years to come,” says Luca Bottura, head of the CERN magnet group.
The dipole- and quadrupole-magnet milestones also send a positive signal about the viability of future hadron colliders beyond the LHC, which are expected to rely on Nb3Sn magnets with fields of up to 16 T. To this end, CERN and the US labs are achieving impressive results in the performance of Nb3Sn conductor in various demonstrator magnets. In February, the CERN magnet group produced a record field of 16.36 T at 1.9 K (16.5 T conductor peak field) in the centre of a short “enhanced racetrack model coil” demonstrator, with no useful aperture, which was developed in the framework of the Future Circular Collider study. In June 2019, as part of the US Magnet Development Programme, a short “cos-theta” dipole magnet with an aperture of 60 mm reached a bore field of 14.1 T at 4.5 K at Fermilab. Beyond magnets, says Rossi, the HL-LHC is also breaking new ground in superconducting-RF crab cavities, advanced material collimators and 120 kA links based on novel MgB2 superconductors.
Next steps
Before they can constitute fully operational accelerator magnets which could be installed in the HL-LHC, both these quadrupole magnets and the dipole magnets must be connected in pairs (the longer CERN quadrupole magnets are single units). Each magnet in a pair has the same winding, and differs only in its mechanical interfaces and details of its electrical circuitry. Tests of the remaining halves of the quadrupole- and dipole-magnet pairs were scheduled to take place in the US and at CERN during the coming months, with the dipole magnet pairs to be installed in the LHC tunnel this year. Given the current global situation, this plan will have to be reviewed, which is now the high-priority discussion within the HL-LHC project.
In a clinical world-first, a proton beam has been used to treat a patient with a ventricular tachycardia, which causes unsynchronised electrical impulses that prevent the heart from pumping blood. On 13 December, a 150 MeV beam of protons was directed at a portion of tissue in the heart of a 73-year-old male patient at the National Center of Oncological Hadrontherapy (CNAO) in Italy – a facility set out 25 years ago by the TERA Foundation and rooted in accelerator technologies developed in conjunction with CERN via the Proton Ion Medical Machine Study (PIMMS). The successful procedure had a minimal impact on the delicate surrounding tissues, and marks a new path in the rapidly evolving field of hadron therapy.
The use of proton beams in radiation oncology, first proposed in 1946 by founding director of Fermilab Robert Wilson, allows a large dose to be deposited in a small and well-targeted volume, reducing damage to healthy tissue surrounding a tumour and thereby reducing side effects. Upwards of 170,000 cancer patients have benefitted from proton therapy at almost 100 centres worldwide, and demand continues to grow (CERN Courier January/February 2018 p32).
The choice by clinicians in Italy to use protons to treat a cardiac pathology was born out of necessity to fight an aggressive form of ventricular tachycardia that had not responded effectively to traditional treatments. The idea is that the Bragg peak typical of light charged ions (by which a beam can deposit a large amount of energy in a small region) can produce small scars in the heart tissues similar to the ones caused by the standard invasive technique of RF cardiac ablation. “To date, the use of heavy particles (protons, carbon ions) in this area has been documented in the international scientific literature only on animal models,” said Roberto Rordorf, head of arrhythmology at San Matteo Hospital, in a press release on 22 January. “The Pavia procedure appears to be the first in the world to be performed on humans and the first results are truly encouraging. For this reason, together with CNAO we are evaluating the feasibility of an experimental clinical study.”
Hadron therapy for all
CNAO is one of just six next-generation particle-therapy centres in the world capable of generating beams of protons and carbon ions, which are biologically more effective than protons in the treatment of radioresistant tumours. The PIMMS programme from which the accelerator design emerged, carried out at CERN from 1996 to 2000, aimed to design a synchrotron optimised for ion therapy (CERN Courier January/February 2018 p25). The first dual-ion treatment centre in Europe was the Heidelberg Ion-Beam Therapy Centre (HIT) in Germany, designed by GSI, which treated its first patient in 2009. CNAO followed in 2011 and then the Marburg Ion-Beam Therapy Centre in Germany (built by Siemens and operated by Heidelberg University Hospital since 2015). Finally, MedAustron in Austria, based on the PIMMS design, has been operational since 2016. Last year, CERN launched the Next Ion Medical Machine Study (NIMMS) as a continuation of PIMMS to carry out R&D into the superconducting magnets, linacs and gantries for advanced hadron therapy. NIMMS will also explore ways to reduce the cost and footprint of hadron therapy centres, allowing more people in different regions to benefit from the treatment (CERN Courier March 2017 p31).
I think that in 20 years’ time cardiac arrhythmias will be mostly treated with light-ion accelerators
“When I decided to leave the spokesmanship of the DELPHI collaboration to devote my time to cancer therapy with light-ion beams I could not imagine that, 30 years later, I would have witnessed the treatment of a ventricular tachycardia with a proton beam and, moreover, that this event would have taken place at CNAO, a facility that has its roots at CERN,” says TERA founder Ugo Amaldi. “The proton treatment recently announced, proposed to CNAO by cardiologists of the close-by San Matteo Hospital to save the life of a seriously ill patient, is a turning point. Since light-ion ablation is non-invasive and less expensive than the standard catheter ablation, I think that in 20 years’ time cardiac arrhythmias will be mostly treated with light-ion accelerators. For this reason, TERA has secured a patent on the use of ion linacs for heart treatments.”
In a former newspaper printing plant in the southern Dutch town of Maastricht, the future of gravitational-wave detection is taking shape. In a huge hall, known to locals as the “big black box”, construction of a facility called ETpathfinder has just got under way, with the first experiments due to start as soon as next year. ETpathfinder will be a testing ground for the new technologies needed to detect gravitational waves in frequency ranges that the present generation of detectors cannot cover. At the same time, plans are being developed for a full-scale gravitational-wave detector, the Einstein Telescope (ET), in the Dutch–Belgian–German border region. Related activities are taking place 1500 km south in the heart of Sardinia, Italy. In 2023, one of these two sites (which have been selected from a total of six possible European locations) will be selected as the location of the proposed ET.
In 2015, the Laser Interferometer Gravitational-Wave Observatory (LIGO), which is based at two sites in the US, made the first direct detection of a gravitational wave. The Virgo observatory near Pisa in Italy came online soon afterwards, and the KAGRA observatory in Japan is about to become the third major gravitational-wave observatory in operation. All are L-shaped laser interferometers that detect relative differences in light paths between mirrors spaced far apart (4 km in LIGO; 3 km in Virgo and KAGRA) at the ends of two perpendicular vacuum tubes. A passing gravitational wave changes the relative path lengths by as little as one part in 1021, which is detectable via the interference between the two light paths. Since 2015, dozens of gravitational waves have been detected from various sources, providing a new window onto the universe. One event has already been linked to astronomical observations in other channels, marking a major step forward in multi-messenger astronomy (CERN Courier December 2017 p17).
Back in time
The ET would be at least 10 times more sensitive than Advanced LIGO and Advanced Virgo, extending its scope for detections and enabling physicists to look back much further in cosmological time. For this reason, the interferometer has to be built at least 200 m underground in a geologically stable area, its mirrors have to operate in cryogenic conditions to reduce thermal disturbance, and they have to be larger and heavier to allow for a larger and more powerful laser beam. The ET would be a triangular laser interferometer with sides of 10 km and four ultra-high vacuum tubes per tunnel. The triangle configuration is equivalent to three overlapping interferometers with two arms each, allowing sources in the sky to be pinpointed via triangulation from just one location instead of several as needed by existing observatories. First proposed more than a decade ago and estimated to cost close to €2 billion, the ET, if approved, is expected to start looking at the sky sometime in the 2030s.
“In the next decade we will implement new technologies in Advanced Virgo and Advanced LIGO, which will enable about a factor-two increase in sensitivity, gaining in detection volume too, but we are reaching the limits of the infrastructure hosting the detectors, and it is clear that at a certain point these will strongly limit the progress you can make by installing new technologies,” explains Michele Punturo of INFN Perugia, who is co-chair of the international committee preparing the ET proposal. “The ET idea and its starting point is to have a new infrastructure capable of hosting further and further evolutions of the detectors for decades.”
Belgian, Dutch and German universities are investing heavily in the ETpathfinder project, which is also funded by European Union budgets for interregional development, and are considering a bid for the ET in the flowing green hills of the border region around Vaals between Maastricht (Netherlands) and Luik (Belgium). A geological study in September 2019 concluded that the area has a soft-soil top layer that provides very good environmental noise isolation for a detector built in granite-like layers 200 m below. Economic studies also show a net benefit, both regional and national, from the high-tech infrastructure the ET would need. But even if ET is not built there, ETpathfinder will still be essential to future gravitational-wave detection, stresses project leader Stefan Hild of Maastricht University. “This will become the testing ground for the disruptive technologies we will need in this field anyway,” he says.
ET in search of home
ETpathfinder is a research infrastructure, not a scale model for the future ET. Its short length means that it is not aimed at detecting gravitational waves at any point in time. The L-shaped apparatus (“Triangulating for the future” image) has two arms about 20 m long, with two large steel suspension towers each containing large mirrors. The arms meet in a central fifth steel optical tower and one of the tubes extends behind the central tower, ending in a sixth tower. The whole facility will be housed in a new climate-controlled clean room inside the hall, and placed on a new low-vibration concrete floor. ETpathfinder is not a single interferometer but consists of two separate research facilities joined at one point for shared instrumentation and support systems. The two arms could be used to test different mirrors, suspensions, temperatures or laser frequencies independently. Those are the parameters Hild and his team are focusing on to further reduce noise in the interferometers and enhance their sensitivity.
Deep-cooling the mirrors is one way to beat noise, says Hild. But it also brings huge new challenges. One is that thermal conductivity of silica glass is not perfect at deep cryogenic temperatures, leading to deformations due to local laser heating. For that reason, pure silicon has to be used, but silicon is not transparent to the conventional 1064 nm laser light used for detecting gravitational waves and to align the optical systems in the detector. Instead, a whole new laser technology at 1550 nm will have to be developed and tested, including fibre-laser sources, beam control and manipulation, and specialised low-noise sensors. “All these key technologies and more need testing before they can be scaled up to the 10 km scales of the future ET,” says Hild. Massive mirrors in pure silicon of metre-sizes have never been built, he points out, nor have silicon wire suspensions for the extreme cold payloads of more than half a tonne. Optoelectronics and sensors at 1550 nm at the noise level required for gravitational-wave detectors are also non-standard.
On paper, the new super-low noise detection technologies to be investigated by ETpathfinder will provide stunning new ways of looking at the universe with the ET. The sensitivity at low frequencies will enable researchers to actually hear the rumblings of space–time hours before spiralling black holes or neutron stars coalesce and merge. Instead of astronomers struggling to point their telescopes at the point in the sky indicated by millisecond chirps in LIGO and Virgo, they will be poised to catch the light from cosmic collisions many billions of light years away.
The Archimedes experiment, which will be situated under 200 m of rock at the Sar-Grav laboratory in the Sos Enattos mine in Sardinia, was conceived in 2002 to investigate the interaction between the gravitational field and vacuum fluctuations. Supported by a group of about 25 physicists from Italian institutes and the European Gravitational Observatory, it is also intended as a “bridge” between present- and next-generation interferometers. A separate project in the Netherlands, ETpathfinder, is performing a similar function (see main text).
Quantum mechanics predicts that the vacuum is a sea of virtual particles which contribute an energy density – although one that is tens of orders of magnitude larger than what is observed. Archimedes will attempt to shed light on the puzzle by clarifying whether virtual photons gravitate or not, essentially testing the equivalent of Archimedes’ principle in vacuum. “If the virtual photons do gravitate then they must follow the gravitational field around the Earth,” explains principal investigator Enrico Calloni of the University of Naples Federico II. “If we imagine removing part of them from a certain volume, creating a bubble, there will be a lack of weight (and pressure differences) in that volume, and the bubble will sense a force directed upwards, similar to the Archimedes force in a fluid. Otherwise, if they do not gravitate, the bubble will not experience any variation in the force even being immersed in the gravitational field.”
The experiment (pictured) will use a Casimir cavity comprising two metallic plates placed a short distance apart so that virtual photons that have too large a wavelength cannot survive and are expelled, enabling Archimedes to measure a variation of the “weight” of the quantum vacuum. Since the force is so tiny, the measurement must be modulated and performed at a frequency where noise is low, says Calloni. This will be achieved by modulating the vacuum energy contained in the cavity using plates made from a high-temperature superconductor, which exhibits transitions from a semiconducting to superconducting state and in doing so alters the reflectivity of the plates. The first prototype is ready and in March the experiment is scheduled to begin six years of data-taking. “Archimedes is a sort of spin-off of Virgo, in the sense that it uses many of the technologies learned with Virgo: low frequency, sensors. And it has a lot of requirements in common with third-generation interferometers like ET: cryogenics and low seismic noise, first and foremost,” explains Calloni. “Being able to rely on an existing lab with the right infrastructure is a very strong asset for the choice of a site for ET.”
Sardinian adventure
The Sos Enattos mine is situated in the wild and mountainous heart of Sardinia, an hour’s drive from the Mediterranean coast. More than 2000 years ago, the Romans (who, having had a hard time conquering the land, christened the region “Barbaria”) excavated around 50 km of underground tunnels to extract lead for their aqueduct pipes. Until it closed activity in 1996, the mine has been the only alternative to livestock-rearing in this area for decades. Today, the locals are hoping that Sos Enattos will be chosen as the site to host the ET. Since 2010, several underground measurement campaigns have been carried out to characterise the site in terms of environmental noise. The regional government of Sardinia is supporting the development of the “Sar-Grav” underground laboratory and its infrastructures with approximately €3.5 million, while the Italian government is supporting the upgrade of Advanced Virgo and the characterisation of the Sos Enattos site with about €17 million, as part of a strategy to make Sardinia a possible site for the ET.
Sar-Grav’s control room was completed late last year, and its first experiment – Archimedes – will soon begin (see “Archimedes weighs in on the quantum vacuum” panel), with others expected to follow. Archimedes will measure the effect of quantum interactions with gravity via the Casimir effect and, at the same time, provide a testbed to verify the technologies needed by a third-generation gravitational-wave interferometer such as the ET. “Archimedes has the same requirements as an underground interferometer: extreme silence, extreme cooling with liquid nitrogen, and the ensuing safety requirements,” explains Domenico D’Urso, a physicist from the University of Sassari and INFN.
Follow the noise
Sardinia is the oldest land in Italy and the only part of the country without significant seismic risk. The island also has a very low population density and thus low human activity. The Sos Enattos mine has very low seismic noise and the most resistant granitic rock, which was used until the 1980s to build the skyscrapers of Manhattan. Walking along the mine’s underground tunnels – past the Archimedes cavern, amidst veins of schist, quartz, gypsum and granite, ancient mining machines and giant portraits of miners bearing witness to a glorious past – an array of instruments can be seen measuring seismic noise; some of which are so sensitive that they are capable of recording the sound of waves washing against the shores of the Thyrrenian sea. “We are talking about really small sensitivities,” continues Domenico. “An interferometer needs to be able to perform measurements of 10–21, otherwise you cannot detect a gravitational wave. You have to know exactly what your system is doing, follow the noise and learn how to remove it.”
With the Einstein Telescope, we have 50 years of history ahead
The open European ET collaboration will spend the next two years characterising both the Sardinian and Netherlands sites, and then choosing which best matches the required parameters. In the current schedule, a technical design report for the ET would be completed in 2025 and, if approved, construction would take place from 2026 with first data-taking during the 2030s. “As of then, wherever it is built, ET will be our facility for decades, because its noise will be so low that any new technology that at present we cannot even imagine could be implemented and not be limited,” says Punturo, emphasising the scientific step-change. Current detectors can see black-hole mergers occurring at a redshift of around one when the universe was six billion years old, Punturo explains, while current detectors at their final sensitivity will achieve a redshift of around two, corresponding to three billion years after the Big Bang. “But we want to observe the universe in its dark age, before stars existed. To do so, we need to increase sensitivity to a redshift tenfold and more,” he says. “With ET, we have 50 years of history ahead. It will study events from the entire universe. Gravitational waves will become a common tool just like conventional astronomy has been for the past four centuries.”
Two detectors, both alike in dignity, sit 100 m underground and 8 km apart on opposite sides of the border between Switzerland and France. Different and complementary in their designs, they stand ready for anything nature might throw at them, and over the past 10 years physicists in the ATLAS and CMS collaborations have matched each other paper for paper, blazing a path into the unknown. And this is only half of the story. A few kilometres around the ring either way sit the LHCb and ALICE experiments, continually breaking new ground in the physics of flavour and colour.
Plans hatched when the ATLAS and CMS collaborations formed in the spring of 1992 began to come to fruition in the mid 2000s. While liquid-argon and tile calorimeters lit up in ATLAS’s cavern, cosmic rays careened through partially assembled segments of each layer of the CMS detector, which was beginning to be integrated at the surface. “It was terrific, we were taking cosmics and everybody else was still in pieces!” says Austin Ball, who has been technical coordinator of CMS for the entire 10-year running period of the LHC so far. “The early cosmic run with magnetic field was a byproduct of our design, which stakes everything on a single extraordinary solenoid,” he explains, describing how the uniquely compact and modular detector was later lowered into its cavern in enormous chunks. At the same time, the colossal ATLAS experiment was growing deep underground, soon to be enveloped by the magnetic field generated by its ambitious system of eight air–core superconducting barrel loops, two end-caps and an inner solenoid. A thrilling moment for both experiments came on 10 September 2008, when protons first splashed off beam stoppers and across the detectors in a flurry of tracks. Ludovico Pontecorvo, ATLAS’s technical coordinator since 2015, remembers “first beam day” as a new beginning. “It was absolutely stunning,” he says. “There were hundreds of people in the control room. It was the birth of the detector.” But the mood was fleeting. On 19 September a faulty electrical connection in the LHC caused a hundred or so magnets to quench, and six tonnes of liquid helium to escape into the tunnel, knocking the LHC out for more than a year.
You have this monster and suddenly it turns into this?
Werner Riegler
The experimentalists didn’t waste a moment. “We would have had a whole series of problems if we hadn’t had that extra time,” says Ball. The collaborations fixed niggling issues, installed missing detector parts and automated operations to ease pressure on the experts. “Those were great days,” agrees Richard Jacobsson, commissioning and run coordinator of the LHCb experiment from 2008 to 2015. “We ate pizza, stayed up nights and slept in the car. In the end I installed a control monitor at home, visible from the kitchen, the living room and the dining room, with four screens – a convenient way to avoid going to the pit every time there was a problem!” The hard work paid off as the detectors came to life once again. For ALICE, the iconic moment was the first low-energy collisions in December 2009. “We were installing the detector for 10 years, and then suddenly you see these tracks on the event display…” reminisces Werner Riegler, longtime technical coordinator for the collaboration. “I bet then-spokesperson Jürgen Schukraft three bottles of Talisker whisky that they couldn’t possibly be real. You have this monster and suddenly it turns into this? Everybody was cheering. I lost the bet.”
The first high-energy collisions took place on 30 March 2010, at a centre-of-mass energy of 7 TeV, three-and-a-half times higher than the Tevatron, and a leap into terra incognita, in the words of ATLAS’s Pontecorvo. The next signal moment came on 8 November with the first heavy-ion collisions, and almost immediate insights into the quark–gluon plasma.
ALICE in wonderland
For a few weeks each year, the LHC ditches its signature proton collisions at the energy frontier to collide heavy ions such as lead nuclei, creating globules of quark–gluon plasma in the heart of the detectors. For the past 10 years, ALICE has been the best-equipped detector in the world to record the myriad tracks that spring from these hot and dense collisions of up to 416 nucleons at a time.
Like LHCb, ALICE is installed in a cavern that previously housed a LEP detector – in ALICE’s case the L3 experiment. Its tracking and particle-identification subdetectors are mostly housed within that detector’s magnet, fixed in place and still going strong since 1989, the only worry a milli-Amp leak current, present since L3 days, which shifters monitor watchfully. Its relatively low field is not a limitation as ALICE’s specialist subject is low-momentum tracks – a specialty made possible by displacing the beams at the interaction point to suppress the luminosity. “The fact that we have a much lower radiation load than ATLAS, CMS and LHCb allows us to use technologies that are very good for low-momentum measurements, which the other experiments cannot use because their radiation-hardness requirements are much higher,” says Riegler, noting that the design of ALICE requires less power, less cooling and a lower material budget. “This also presents an additional challenge in data processing and analysis in terms of reconstructing all these low-momentum particles, whereas for the other experiments, this is background that you can cut away.” The star performer in ALICE has been the time-projection chamber (TPC), he counsels me, describing a detector capable of reconstructing the 8000 tracks per rapidity unit that were forecast when the detector was designed.
But nature had a surprise in store when the LHC began running with heavy ions. The number of tracks produced was a factor three lower than expected, allowing ALICE to push the TPC to higher rates and collect more data. By the end of Run 2, a detector designed to collect “minimum- bias” events at 50 Hz was able to operate at 1 kHz – a factor 20 larger than the initial design.
The discovery of jet quenching came simply by looking at event displays in the control room
Ludovico Pontecorvo
The lower-than-expected track multiplicities also had a wider effect among the LHC experiments, making ATLAS, CMS and LHCb highly competitive for certain heavy-ion measurements, and creating a dynamic atmosphere in which insights into the quark–gluon plasma came thick and fast. Even independently of the less-taxing-than-expected tracking requirements, top-notch calorimetry allowed immediate insights. “The discovery of jet quenching came simply by looking at event displays in the control room,” confirms Pontecorvo of ATLAS. “You would see a big jet that wasn’t counterbalanced on the other side of the detector. This excitement was transmitted across the world.”
Keeping cool
Despite the exceptional and expectation-busting performance of the experiments, the first few years were testing times for the physicists and engineers tasked with keeping the detectors in rude health. “Every year we had some crisis in cooling the calorimeters,” recalls Pontecorvo. Fortunately, he says, ATLAS opted for “under-pressure” cooling, which prevents water spilling in the event of a leak, but still requires a big chunk of the calorimeter to be switched off. The collaboration had to carry out spectacular interventions, and put people in places that no one would have guessed would be possible, he says. “I remember crawling five metres on top of the end-cap calorimeter to arrive at the barrel calorimeter to search for a leak, and using 24 clamps to find which one of 12 cooling loops had the problem – a very awkward situation!” Ball recalls experiencing similar difficulties with CMS. There are 11,000 joints in the copper circuits of the CMS cooling system, and a leak in any one is enough to cause a serious problem. “The first we encountered leaked into the high-voltage system of the muon chambers, down into the vacuum tank containing the solenoid, right through the detector, which like the LHC itself is on a slope, and out the end as a small waterfall,” says Ball.
The arresting modularity of CMS, and the relative ease of opening the detector – admittedly an odd way to describe sliding a 1500-tonne object along the axis of a 0.8 mm thick beam pipe – proved to be the solution to many problems. “We have exploited it relentlessly from day one,” says Ball. “The ability to access the pixel tracker, which is really the heart of CMS, with the highest density of sensitive channels, was absolutely vital – crucial for repairing faults as well as radiation damage. Over the course of five or six years we became very efficient at accessing it. The performance of the whole silicon tracking system has been outstanding.”
The early days were also challenging for LHCb, which is set up to reconstruct the decays of beauty hadrons in detail. The dawning realisation that the LHC would run optimally with fewer but brighter proton bunches than originally envisaged set stern tests from the start. From LHCb’s conception to first running, all of the collaboration’s discussions were based on the assumption that the detector would veto any crossing of protons where there would be more than one interaction. In the end, faced with a typical “pile-up” of three, the collaboration had to reschedule its physics priorities and make pragmatic decisions about the division of bandwidth in the high-level trigger. “We were faced with enormous problems: synchronisation crashes, event processing that was taking seconds and getting stuck…,” recalls Jacobsson. “Some run numbers, such as 1179, still send shivers down the back of my spine.” By September, however, they had demonstrated that LHCb was capable of running with much higher pile-up than anybody had thought possible.
No machine has ever been so stable in its operational mode
Rolf Lindner
Necessity was the mother of invention. In 2011 and 2012 LHCb introduced a feedback system that maintains a manageable luminosity during each fill by increasing the overlap between the colliding beams as protons “burn out” in collisions, and the brightness of the bunches decreases. When Jacobsson and his colleagues mentioned it to the CERN management in September 2010, the then director of accelerators, Steve Myers, read the riot act, warning of risks to beam stability, recalls Jacobsson. “But since I had a few good friends at the controls of the LHC, we could carefully and quietly test this, and show that it produced stable beams. This changed life on LHCb completely. The effect was that we would have one stable condition throughout every fill for the whole year – perfect for precision physics.”
Initially, LHCb had planned to write events at 200 Hz, recalls Rolf Lindner, the experiment’s longtime technical coordinator, but by the end of Run 1, LHCb was collecting data at up to 10 kHz, turning offline storage, processing and “physics stripping” into an endless fire fight. Squeezing every ounce of performance out of the LHC generated greater data volumes than anticipated by any of the experiments, and even stories (probably apocryphal) of shifters running down to local electronics stores to buy data discs because they were running out of storage. “The LHC would run for several months with stable beams for 60% of every 24 hours in a day,” says Lindner. “No machine has ever been so stable in its operational mode.”
Engineering all-stars
The eyes of the world turned to ATLAS and CMS on 4 July 2012 as the collaborations announced the discovery of a new boson – an iconic moment to validate countless hours of painstaking work by innumerable physicists, engineers and computer scientists, which is nevertheless representative of just one of a multitude of physics insights made possible by the LHC experiments (see LHC at 10: the physics legacy). The period running up to the euphoric Higgs discovery had been smooth for all except LHCb, who had to scramble to disprove unfounded suggestions that their dipole magnet, occasionally reversed in field to reduce systematic uncertainties, was causing beam instabilities. But new challenges would shortly follow. Chief among several hair-raising moments in CMS was the pollution of the magnet cryogenic system in 2015 and 2016, which caused instability in the detector’s cold box and threatened the reliable operation of the superconducting solenoid surrounding the tracker and calorimeters. The culprit turned out to be superfluous lubricant – a mere half a litre of oil, now in a bottle in Ball’s office – which clogged filters and tiny orifices crucial to the cyclical expansion cycle used to cool the helium. “By the time we caught on to it, we hadn’t just polluted the cold box, we had polluted the whole of the distribution from upstairs to downstairs,” he recalls, launching into a vivid account of seat-of-the-pants interventions, and also noting that the team turned their predicament into an opportunity. “With characteristic physics ingenuity, and faced with spoof versions of the CMS logo with straightened tracks, we exploited data with the magnet off to calibrate the calorimeters and understand a puzzling 750 GeV excess in the diphoton invariant mass distribution,” he says.
Now I look back on the cryogenic crisis as the best project I ever worked on at CERN
With resolute support from CERN, bold steps were taken to fix the problem. It transpired that slightly-undersized replaceable filter cartridges were failing to remove the oil after it was mixed with the helium to lubricate screw-turbine compressors in the surface installation. “Now I look back on the cryogenic crisis as the best project I ever worked on at CERN, because we were allowed to assemble this cross-departmental superstar engineering team,” says Ball. “You could ask for anyone and get them. Cryogenics experts, chemists and mechanical engineers… even Rolf Heuer, then the Director-General, showed up frequently. The best welders basically lived in our underground area – you could normally only see their feet sticking out from massive pipework. If you looked carefully you might spot a boot. It’s a complete labyrinth. That one will stick with me for a long time. A crisis can be memorable and satisfying if you solve it.”
Heroic efforts
During the long shutdown that followed, the main task for LHCb was to exchange a section of beryllium beam pipe in which holes had been discovered and meticulously varnished over in haste before being used in Run 1. At the same time, right at the end of an ambitious and successful consolidation and improvement programme, CMS suffered the perils of extraordinarily dense circuit design when humid air condensed onto cold silicon sensor modules that had temporarily been moved to a surface clean room. 10% of the pixels short-circuited when it was powered up again, and heroic efforts were needed to re-manufacture replacements and install them in time for the returning LHC beams. Meanwhile, wary of deteriorating optical readout, ATLAS refurbished their pixel-detector cabling, taking electronics out of the detector to make it serviceable and inserting a further inner pixel layer just 33 mm from the beam pipe to up their b-tagging game. The bigger problem was mechanical shearing of the bellows that connect the cryostat of one of the end-cap toroids to the vacuum system – the only problem experienced so far with ATLAS’s ambitious magnet system. “At the beginning people speculated that with eight superconducting coils, each independent from the others, we would experience one quench after another, but they have been perfect really,” confirms Pontecorvo. Combined with the 50-micron alignment of the 45 m-long muon detector, ATLAS has exceeded the design specifications for resolving the momentum of high-momentum muons – just one example of a pattern repeated across all the LHC detectors.
As the decade wore on, the experiments streamlined operations to reach unparalleled performance levels, and took full advantage of technical and end-of-year stops to keep their detectors healthy. Despite their very high-luminosity environments, ATLAS and CMS pushed already world-beating initial data-taking efficiencies of around 90% beyond the 95% mark. “ATLAS and CMS were designed to run with an average pile-up of 20, but are now running with a pile-up of 60. This is remarkable,” states Pontecorvo.
Accelerator rising
At 10, with thousands of physics papers behind them and many more stories to tell, the LHC experiments are as busy as ever, using the second long shutdown, which is currently underway, to install upgrades, many of which are geared to the high-luminosity LHC (HL-LHC) due to operate later this decade. Many parts are being recycled, for example with ALICE’s top-performing TPC chambers donated to Fermilab for the near detector of the DUNE long-baseline neutrino-oscillation experiment. And major engineering challenges remain. A vivid example is that the LHC tunnel, carved out of water-laden rock 30 years ago, is rising up, while the experiments – particularly the very compact CMS, which has a density almost the same as rock – remain fixed in place, counterbalancing upthrust due to the removed rock with their weight. CMS faces the greatest challenge due to the geology of the region, explains Ball. “The LHC can use a corrector magnet to adjust the level of the beam, but there is a risk of running out of magnetic power if the shifts are big. Just a few weeks ago they connected a parallel underground structure for HL-LHC equipment, and the whole tunnel went up 3 mm almost overnight. We haven’t solved that one yet.”
Most of all, it is important to acknowledge the dedication of the people who run the experiments
Ludovico Pontecorvo
Everyone I interviewed agrees wholeheartedly on one crucial point. “Most of all, it is important to acknowledge the dedication of the people who run the experiments,” explains Pontecorvo of ATLAS, expressing a sentiment emphasised by his peers on all the experiments. “These people are absolutely stunning. They devote their life to this work. This is something that we have to keep and which it is not easy to keep. Unfortunately, many feel that this work is undervalued by selection committees for academic positions. This is something that must change, or our work will finish – as simple as that.”
Pontecorvo hurries out of the door at the end of our early-morning interview, hastily squeezed into a punishing schedule. None of the physicists I interviewed show even a smidgen of complacency. Ten years in, the engineering and technological marvels that are the four biggest LHC experiments are just getting started.
The start-up of the LHC was an exciting time and the culmination of years of work, made manifest in the process of establishing circulating beams, ramping, squeezing and producing the first collisions. The two major events of the commissioning era were first circulating beams on 10 September 2008 and first high-energy collisions on 30 March 2010. For both of these events the CERN press office saw fit to invite the world’s media, set up satellite links, arrange numerous interviews and such. Combined with the background attention engendered by the LHC’s potential to produce miniature black holes and the LHC’s supporting role in the 2009 film Angels and Demons, the LHC enjoyed a huge amount of coverage, and in some sense became a global brand in the process (CERN Courier September 2018 p44).
The LHC is one of biggest, most complex and powerful instruments ever built. The large-scale deployment of the main two-in-one dipoles and quadrupoles cooled to 1.9 K by superfluid helium is unprecedented even in particle physics. Many unforeseen issues had to be dealt with in the period before start-up. A well-known example was that of the “collapsing fingers”. In the summer of 2007, experts realised that the metallic modules responsible for the electrical continuity between different vacuum pipe sections in the magnet interconnects could occasionally become distorted as the machine was warmed up. This distortion led to a physical obstruction of the beam pipe. The solution was surprisingly low-tech: to blow a ping-pong-sized ball fitted with a 40 MHz transmitter through the pipes and find out where it got stuck.
The commissioning effort was clearly punctuated by the electrical incident that occurred during high-current tests on 19 September 2008, just nine days after the success of “first beam day”. Although the incident was a severe blow to CERN and the LHC community, it did provide a hiatus of which full use was made (see A labour of love). The LHC and experiments returned at “an unprecedented state of readiness” and beam was circulated again on 20 November 2009. Rapid progress followed. Collisions with stable beam conditions were quickly established at 450 GeV, and a ramp to the maximum beam energy at the time (1.18 TeV, compared to the Tevatron’s 0.98 TeV) was successfully achieved on 30 November. All beam-based systems were at least partially commissioned and LHC operators managed to start to master the control of a hugely complex machine.
After the 2009 Christmas technical stop, which saw continued deployment of the upgraded quench-protection system that had been put in place following the 2008 incident, commissioning started again in the new year. Progress was rapid, with first colliding beams at 3.5 TeV being established on 30 March 2010. It was a tense day in the control room with the scheduled collisions delayed by two unsuccessful ramps and all under the watchful eye of the media. In the following days, squeeze-commissioning successfully reduced the β* parameter (which is related to the transverse size of the beam at the interaction points) to 2.0 m in ATLAS and CMS. Stable beams were declared, and the high-energy exploitation of the four main LHC experiments could begin in earnest.
Tales from Run 1
Essentially 2010 was devoted to commissioning and then establishing confidence in operational procedures and the machine protection system before starting the process of ramping up the number of bunches in the beam.
In June the decision was taken to go for bunches with nominal population (1.15 × 1011 protons), which involved another extended commissioning period. Up to this point, only around one fifth of the nominal bunch population was used. To further increase the number of bunches, the move to bunch trains separated by 150 ns was made and the crossing angles spanning the experiments’ insertion regions brought in. This necessitated changes to the tertiary collimators and a number of ramps and squeezes. We then performed a carefully phased increase in total intensity. The proton run finished with beams of 368 bunches of around 1.2 × 1011 protons per bunch, and a peak luminosity of 2.1 × 1032 cm–2s–1, followed by a successful four-week long lead–lead ion run.
The initial 50 and 25 ns intensity ramp-up phase was tough going
In 2011 it was decided to keep the LHC beam energy at 3.5 TeV, and to operate with 50 ns bunch spacing – opening the way to significantly more bunches per beam. Following several weeks of commissioning, a staged ramp-up in the number of bunches took us to a maximum of 1380 bunches. Reducing the transverse size of the beams delivered by the injectors and gently increasing the bunch population resulted in a peak luminosity of 2.4 × 1033 cm–2s–1 and some healthy luminosity-delivery rates. Following a reduction in β* in ATLAS and CMS from 1.5 m to 1.0 m, and further gradual increases in bunch population, the LHC achieved a peak luminosity of 3.8 × 1033 cm–2s–1 – well beyond expectations at the start of the year – and delivered a total of around 5.6 fb–1 to both ATLAS and CMS.
2012 was a production year at an increased beam energy of 4 TeV, with 50 ns bunch spacing and 1380 bunches. A decision to operate with tighter collimator settings allowed a more aggressive squeeze to a β* of 0.6 m, and the peak luminosity was quickly close to its maximum for the year, followed by determined and long-running attempts to improve peak performance. Beam instabilities, although never debilitating, were a reoccurring problem and there were phases when they cut into operational efficiency. By the middle of the year another 6 fb–1 had been delivered to both ATLAS and CMS. Combined with the 2011 dataset, this paved the way for the announcement of the Higgs discovery on 4 July 2012. It was a very long operational year and included the extension of the proton–proton run until December, resulting in the shift of a four-week-long proton–lead run to 2013. Integrated-luminosity rates were healthy at around the 1 fb–1 per-week level and this allowed a total for the year of about 23 fb–1 to be delivered to both ATLAS and CMS.
Caused by beam-induced radiation to tunnel electronics, these were a serious cause of inefficiency in the LHC’s early days. However, the problem had been foreseen and its impact was considerably reduced following a sustained programme of mitigation measures – including shielding campaigns prior to the 2011 run.
Unidentified falling objects
Microscopic particles of the order of 10 microns across, which fall from the top of the vacuum chamber or beam screen, become ionised by collisions with circulating protons and are then repelled by the positively charged beam. While interacting with the circulating protons they generate localised beam loss, which may be sufficient to dump the beam or, in the limit, cause a quench. During the first half of 2015 they were a serious issue, but happily they have subsequently conditioned down in frequency.
Beam-induced heating
This is where regions of the LHC near the beam become too warm, and has been a long-running issue. Essentially, all cases have been local and, in some way, due to non-conformities either in design or installation. Design problems have affected the injection protection devices and the mirror assemblies of the synchrotron radiation telescopes, while installation problems have occurred in a low number of vacuum assemblies. These issues have all been addressed and are not expected to be a problem in the long term.
Beam instabilities
This was an interesting problem that occasionally dogged operations. Operations with 25 ns bunch spacing and lower bunch population have meant that intrinsically instabilities should have been less of an issue. However, high electron cloud (see “Electron cloud effects”) also proved to be a driver and defence mechanisms were deployed in the form of high-chromaticity, high-octupole field strength, and the all-important transverse damper system.
Electron cloud effects
These result from an avalanche-like process in which electrons from gas ionisation or photo-emission are accelerated in the electromagnetic field of the beam and hit the beam-chamber walls with energies of a few hundreds of eV, producing more electrons. This can lead to beam oscillations and blow-up of the proton bunches. “Scrubbing”, the deliberate invocation of high electron cloud with beam, provides a way to reduce or suppress subsequent electron cloud build-up. Extensive scrubbing was needed for 25 ns running. Conditioning thereafter has been slow and the heat load from electron cloud to cryogenics system remained a limitation in 2018.
To Run 2 and beyond
In early 2015 the LHC emerged from “long-shutdown one”. The aims were to re-commission the machine without beam following major consolidation and upgrades, and from a beam perspective to safely establish operations at 6.5 TeV with 25 ns bunch spacing and around 2800 bunches. This was anticipated to be more of a challenge than previous operations at 4 TeV with 50 ns beams. Increased energy implies lower quench margins and thus lower tolerance to beam loss, with hardware pushed closer to maximum with potential knock-on effects to availability. A 25 ns beam was anticipated to have significantly higher electron-cloud effects (see “Five phrases LHC operators learned to love” box) than that experienced with 50 ns; in addition, there was a higher total beam current and higher intensity per injection. All of these factors came into play to make 2015 a challenging year.
The initial 50 and 25 ns intensity ramp-up phase was tough going and had to contend with a number of issues, including earth faults, unidentified falling objects, an unidentified aperture restriction in a main dipole, and radiation affecting specific electronic components in the tunnel. Nonetheless, the LHC was able to operate with up to 460 bunches and deliver some luminosity to the experiments, albeit with poor efficiency. The second phase of the ramp-up, following a technical stop at the start of September, was dominated by the electron–cloud-generated heat load and the subsequent challenge for the cryogenics, which had to wrestle with transients and operation close to their cooling power limits. The ramp-up in number of bunches was consequently slow but steady, culminating in the final figure for the year of 2244 bunches per beam. Importantly, the electron cloud generated during physics operations at 6.5 TeV served to slowly condition the surface of the beam screens in the cold sectors and so reduce the heat load at a given intensity. As time passed, this effect opened a margin for the use of more bunches.
The overall machine availability remained respectable with around 32% of the scheduled time spent in “stable beams” mode during the final period of proton–proton physics from September to November. By the end of the 2015 proton run, 2244 bunches per beam were giving peak luminosities of 5.5 × 1033 cm–2s–1 in the high-luminosity experiments, with a total integrated luminosity of around 4 fb–1 delivered to both ATLAS and CMS. Levelled luminosities of 3 × 1032 cm–2s–1 in LHCb and 5 × 1030 cm–2s–1 in ALICE were provided throughout the run.
A luminous future
Following an interesting year, 2016 was the first full year of exploitation at 6.5 TeV. The beam size at the interaction point was further reduced (β* = 0.4 m) and the LHC design luminosity of 1034 cm–2s–1 was achieved. Reasonable machine availability allowed a total of 40 fb–1 to be delivered to both ATLAS and CMS. 2017 saw a further reduction in beam size at the interaction point (β* = 0.3 m), which, together with small beams from the injectors, gave a peak luminosity of 2.2 × 1034 cm–2s–1. Despite the effects of an accidental ingress of air into the beam vacuum during the winter technical stop, around 50 fb–1 was delivered to ATLAS and CMS.
Not only can a 27 km superconducting collider work, it can work well!
2018 essentially followed the set-up of 2017 with a squeeze to β* = 0.3 m in ATLAS and CMS. The effects of the air ingress lingered on, limiting the maximum bunch intensity to approximately 1.2 × 1011. Despite this, the peak luminosity was systematically close to 2 × 1034 cm–2s–1 and around 63 fb–1 was delivered to ATLAS and CMS. Somewhat more integrated luminosity was possible thanks to the novel luminosity levelling strategy pursued. This involved continuous adjustment of the crossing angle in stable beams, and for the first time the LHC dynamically changed the optics in stable-beams mode, with β* reduced from 0.30 to 0.27 to 0.25 m while colliding. The year finished with a very successful lead–ion run, helped by the impressive ion delivery from the injectors. In December 2018 the machine entered long-shutdown two, recovery from which is scheduled in 2021.
It is nearly 12 years since first beam, and 10 since first high-energy operations at the LHC. The experience has shown that, remarkably, not only can a 27 km superconducting collider work, it can work well! This on the back of some excellent hardware system performance, impressive availability, high beam quality from the injectors and some fundamental operational characteristics of the LHC. Thanks to the work of many, many people over the years, the LHC is now well understood and continues to push our understanding of how to operate high-energy hadron colliders and to surpass expectations. Today, as plans for Run 3 take shape and work advances on the challenging magnets needed for the high-luminosity LHC upgrade, things promise to remain interesting.
Particle physicists have long coveted the advantages of a muon collider, which could offer the precision of a LEP-style electron–positron collider without the energy limitations imposed by synchrotron-radiation losses. The clean neutrino beams that could be produced by bright and well-controlled muon beams could also drive a neutrino factory. In a step towards demonstrating the technical feasibility of such machines, the Muon Ionisation Cooling Experiment (MICE) collaboration has published results showing that muon beams can be “cooled” in phase space.
“Muon colliders can in principle reach very high centre-of-mass energies and luminosities, allowing unprecedented direct searches of new heavy particles and high-precision tests of standard phenomena,” says accelerator physicist Lenny Rivkin of the Paul Scherrer Institute in Switzerland, who was not involved in the work. “Production of bright beams of muons is crucial for the feasibility of these colliders and MICE has delivered a detailed characterisation of the ionisation-cooling process – one of the proposed methods to achieve such muon beams. Additional R&D is required to demonstrate the feasibility of such colliders.”
MICE has delivered a detailed characterisation of the ionisation-cooling process
Lenny Rivkin
The potential benefits of a muon collider come at a price, as muons are unstable and much harder to produce than electrons. This imposes major technical challenges and, not least, a 2.2 µs stopwatch on accelerator physicists seeking to accelerate muons to longer lifetimes in the relativistic regime. MICE has demonstrated the essence of a technique called ionisation cooling, which squeezes the watermelon-sized muon bunches created by smashing protons into targets into a form that can be fed into the accelerating structures of a neutrino factory or the more advanced subsequent cooling stage required for a muon collider – all on a time frame short compared to the muon lifetime.
An alternative path to a muon collider or neutrino factory is the recently proposed Low Emittance Muon Accelerator (LEMMA) scheme, whereby a naturally cool muon beam would be obtained by capturing muon–antimuon pairs created in electron–positron annihilations.
Playing it cool
Based at Rutherford Appleton Laboratory (RAL) in the UK, and two decades in the making, MICE set out to reduce the spatial extent, or more precisely the otherwise approximately conserved phase-space volume, of a muon beam by passing it through a low-Z material while tightly focused, and then restoring the lost longitudinal momentum in such a way that the beam remains bunched and matched. This is only possible in low-Z materials where multiple scattering is small compared to energy loss via ionisation. The few-metre long MICE facility, which precisely measured the phase-space coordinates of individual muons upstream and downstream of the absorber (see figure), received muons generated by intercepting the proton beam from the ISIS facility with a cylindrical titanium target. The absorber was either liquid hydrogen in a tank with thin windows or solid lithium hydride, in both cases surrounded by coils to achieve the necessary tight focus, and maximise transverse cooling.
A full muon-ionisation cooling channel would work by progressively damping the transverse momentum of muons over multiple cooling cells while restoring lost longitudinal momentum in radio-frequency cavities. However, due to issues with the spectrometer solenoids and the challenges of integrating the four-cavity linac module with the coupling coil, explains spokesperson Ken Long of Imperial College London, MICE adopted a simplified design without cavities. “MICE has demonstrated ionisation cooling,” says Long. The next issues to be addressed, he says, are to demonstrate the engineering integration of a demonstrator in a ring, cooling down to the lower emittances needed at a muon collider, and investigations into the effect of bulk ionisation on absorber materials. “The execution of a 6D cooling experiment is feasible – and is being discussed in the context of the Muon Collider Working Group.”
Twists and turns
The MICE experiment took data during 2017 and the collaboration confirmed muon cooling by observing an increased number of “low-amplitude” muons after the passage of the muon beam through an absorber. In this context, the amplitude is an additive contribution to the overall emittance of the beam, with a lower emittance corresponding to a higher density of muons in transverse phase space. The feat presented some extraordinary challenges, says MICE physics coordinator Chris Rogers of RAL. “We constructed a densely packed 12-coil and three-cryostat magnet assembly, with up to 5 MJ of stored energy, which was capable of withstanding 2 MN inter-coil forces,” he says. “The muons were cooled in a removable 22-litre vessel of potentially explosive liquid hydrogen contained by extremely thin aluminium windows.” The instrumentation developed to measure the correlations between the phase-space coordinates introduced by the solenoidal field is another successful outcome of the MICE programme, says Rogers, making a single-particle analysis possible for the first time in an accelerator-physics experiment.
“We started MICE in 2000 with great enthusiasm and a strong team from all continents,” says MICE founding spokesperson Alain Blondel of the University of Geneva. “It has been a long and difficult road, with many practical novelties to solve, however the collaboration has held together with exceptional resilience and the host institution never failed us. It is a great pride to see the demonstration achieved, just at a time when it becomes evident to many new people that we must include muon machines in the future of particle physics.”
This past June in Chamonix, CERN hosted the 12th edition of an international workshop dedicated to the development and application of high-gradient and high-frequency linac technology. These technologies are making accelerators more compact, less expensive and more efficient, and broadening their range of applications. The workshop brought together over seventy 70 and engineers involved in a wide range of accelerator applications, with common interest in the use and development of normal-conducting radio-frequency cavities with very high accelerating gradients ranging from around 50 MV/m to above 100 MV/m.
Applications for high-performance linacs such as these include the Compact Linear Collider (CLIC), compact XFELs and inverse-Compton-scattering photon sources, medical accelerators, and specialised devices such as radio-frequency quadrupoles, transverse deflectors and energy-spread linearisers. In recent years the latter two devices have become essential to achieving low emittances and short bunch lengths in high-performance electron linacs of many types, including superconducting linacs. In the coming years, developments from the high-gradient community will be increasing the energy of beams in existing facilities through retrofit programs, for example in an energy upgrade of the FERMI free-electron laser. In the medium term, a number of new high-gradient linacs are being proposed, such as the room-scale X-ray-source SMART*LIGHT, the linac for the advanced accelerator concept research accelerator EUPRAXIA, and a linac to inject electrons into CERN’s Super Proton Synchrotron for a dark-matter search. The workshop also covered fundamental studies of the very complex physical effects that limit the achievable high gradients, such as vacuum arcing, which is one of the main limitations for future technological advances.
Vacuum arcing is one of the main limitations for future technological advances
Originated by the CLIC study, the focus of the workshop series has grown to encompass high-gradient radio-frequency design, precision manufacture, assembly, power sources, high-power operation and prototype testing. It is also notable for having a strong industrial participation, and plays an important role in broadening the applications of linac technology by highlighting upcoming hardware to companies. The next workshop in the series will be hosted jointly by SLAC and Los Alamos and take place on the shore of Lake Tahoe from 8 to 12 June.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.