

While poring over increasingly voluminous datasets, the LHC collaborations are making sure that students and scientists of tomorrow can revisit the ground-breaking analyses of today.

In the 17th century, Galileo Galilei looked at the moons of Jupiter through a telescope and recorded his observations in his now-famous notebooks. Galileo’s notes – his data – survive to this day and can be reviewed by anyone around the world. Students, amateurs and professionals can replicate Galileo’s data and results – a tenet of the scientific method.
In particle physics, with its unique and expensive experiments, it is practically impossible for others to attempt to reproduce the original work. When it is impractical to gather fresh data to replicate an analysis, we settle for reproducing the analysis with the originally obtained data. However, a 2013 study by researchers at the University of British Columbia, Canada, estimates that the odds of scientific data existing in an analysable form reduce by about 17% each year.
Indeed, just a few years down the line it might not even be possible for researchers to revisit their own data due to changes in formats, software or operating systems. This has led to growing calls for scientists to release and archive their data openly. One motivation is moral: society funds research and so should have access to all of its outputs. Another is practical: a fresh look at data could enable novel research and lead to discoveries that may have eluded earlier searches.
Like open-access publishing (see A turning point for open-access publishing), governments have started to impose demands on scientists regarding the availability and long-term preservation of research data. The European Commission, for example, has piloted the mandatory release of open data as part of its Horizon 2020 programme and plans to invest heavily in open data in the future. An increasing number of data repositories have been established for life and medical sciences as well as for social sciences and meteorology, and the idea is gaining traction across disciplines. Only days after they announced the first observation of gravitational waves, the LIGO and VIRGO collaborations made public their data. NASA also releases data from many of its missions via open databases, such as exoplanet catalogues. The Natural History Museum in London makes data from millions of specimens available via a website and, in the world of art, the Rijksmuseum in Amsterdam provides an interface for developers to build apps featuring historic artworks.
Data levels
The open-data movement is of special interest to particle physics, owing to the uniqueness and large volume of datasets involved in discoveries such as that of the Higgs boson at the Large Hadron Collider (LHC). The four main LHC experiments have started to periodically release their data in an open manner, and these data can be classified into four levels. The first consists of the data shown in final publications, such as plots and tables, while the second concerns datasets in a simplified format that are suitable for “lightweight” analyses in educational or similar contexts. The third level involves the data being used for analysis by the researchers themselves, requiring specialised code and dedicated computing resources, and the final level with the highest complexity is the raw data generated by the detectors, which requires petabytes of storage and, uncalibrated, is not of much use without being fed to the third tier.
In late 2014 CERN launched an open-data portal and released research data from the LHC for the first time. The data, collected by the CMS experiment, represented half the level-three data recorded in 2010. The ALICE experiment has also released level-three data from proton–proton as well as lead–lead collisions, while all four collaborations – including ATLAS and LHCb – have released subsets of level-two data for education and outreach purposes.
Proactive policy
The story of open data at CMS goes back to 2011. “We started drafting an open-data policy, not because of pressure from funding agencies but because defining our own policy proactively meant we did not have an external body defining it for us,” explains Kati Lassila-Perini, who leads the collaboration’s data-preservation project. CMS aims to release half of each year’s level-three data three years after data taking, and 100% of the data within a ten-year window. By guaranteeing that people outside CMS can use these data, says Lassila-Perini, the collaboration can ensure that the knowledge of how to analyse the data is not lost, while allowing people outside CMS to look for things the collaboration might not have time for. To allow external re-use of the data, CMS released appropriate metadata as well as analysis examples. The datasets soon found takers and, in 2017, a group of theoretical physicists not affiliated with the collaboration published two papers using them. CMS has since released half its 2011 data (corresponding to around 200 TB) and half its 2012 data (1 PB), with the first releases of level-three data from the LHC’s Run 2 in the pipeline.
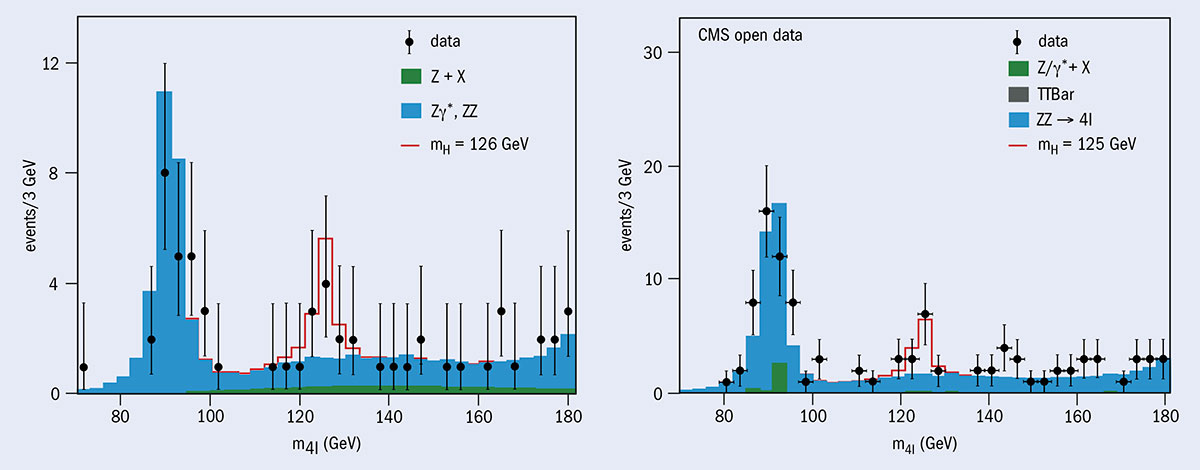
The LHC collaborations have been releasing simpler datasets for educational activities from as early as 2011, for example for the International Physics Masterclasses that involve thousands of high-school students around the globe each year. In addition, CMS has made available several Jupyter notebooks – a browser-based analysis platform named with a nod to Galileo – in assorted languages (programming and human) that allow anyone with an internet connection to perform a basic analysis. “The real impact of open data in terms of numbers of users is in schools,” says Lassila-Perini. “It makes it possible for young people with no previous contact with coding to learn about data analysis and maybe discover how fascinating it can be.” Also available from CMS are more complex examples aimed at university-level students.
Open-data endeavours by ATLAS are very much focused on education, and the collaboration has provided curated datasets for teaching in places that may not have substantial computing resources or internet access. “Not even the documentation can rely on online content, so everything we produce needs to be self-contained,” remarks Arturo Sánchez Pineda, who coordinates ATLAS’s open-data programme. ATLAS datasets and analysis tools, which also rely on Jupyter notebooks, have been optimised to fit on a USB memory stick and allow simplified ATLAS analyses to be conducted just about anywhere in the world. In 2016, ATLAS released simplified open data corresponding to 1 fb–1 at 8 TeV, with the aim of giving university students a feel for what a real particle-physics analysis involves.
ATLAS open data have already found their way into university theses and have been used by people outside the collaboration to develop their own educational tools. Indeed, within ATLAS, new members can now choose to work on preparing open data as their qualification task to become an ATLAS co-author, says Sánchez Pineda. This summer, ATLAS will release 10 fb–1 of level-two data from Run 2, with more than 100 simulated physics processes and related resources. ATLAS does not provide level-three data openly and researchers interested in analysing these can do so through a tailored association programme, which 80 people have taken advantage of so far. “This allows external scientists to rely on ATLAS software, computing and analysis expertise for their project,” says Sánchez Pineda.
Fundamental motivation
CERN’s open-data portal hosts and serves data from the four big LHC experiments, also providing many of the software tools including virtual machines to run the analysis code. The OPERA collaboration recently started sharing its research data via CERN and other particle-physics collaborations are interested in joining the project.
Although high-energy physics has made great strides in providing open access to research publications, we are still in the very early days of open data. Theorist Jesse Thaler of MIT, who led the first independent analysis using CMS open data, acknowledges that it is possible for people to get their hands on coveted data by joining an experimental collaboration, but sees a much brighter future with open data. “What about more exploratory studies where the theory hasn’t yet been invented? What about engaging undergraduate students? What about examining old data for signs of new physics?” he asks. These provocative questions serve as fundamental motivations for making all data in high-energy physics as open as possible.





