

The LHC Olympics and Dark Machines data challenges stimulated innovation in the use of machine learning to search for new physics, write Benjamin Nachman and Melissa van Beekveld.
The need for innovation in machine learning (ML) transcends any single experimental collaboration, and requires more in-depth work than can take place at a workshop. Data challenges, wherein simulated “black box” datasets are made public, and contestants design algorithms to analyse them, have become essential tools to spark interdisciplinary collaboration and innovation. Two have recently concluded. In both cases, contestants were challenged to use ML to figure out “what’s in the box?”
LHC Olympics
The LHC Olympics (LHCO) data challenge was launched in autumn 2019, and the results were presented at the ML4Jets and Anomaly Detection workshops in spring and summer 2020. A final report summarising the challenge was posted to arXiv earlier this year, written by around 50 authors from a variety of backgrounds in theory, the ATLAS and CMS experiments, and beyond. The name of this community effort was inspired by the first LHC Olympics that took place more than a decade ago, before the start of the LHC. In those olympics, researchers were worried about being able to categorise all of the new particles that would be discovered when the machine turned on. Since then, we have learned a great deal about nature at TeV energy scales, with no evidence yet for new particles or forces of nature. The latest LHC Olympics focused on a different challenge – being able to find new physics in the first place. We now know that new physics must be rare and not exactly like what we expected.
In order to prepare for rare and unexpected new physics, organisers Gregor Kasieczka (University of Hamburg), Benjamin Nachman (Lawrence Berkeley National Laboratory) and David Shih (Rutgers University) provided a set of black-box datasets composed mostly of Standard Model (SM) background events. Contestants were charged with identifying any anomalous events that would be a sign of new physics. These datasets focused on resonant anomaly detection, whereby the anomaly is assumed to be localised – a “bump hunt”, in effect. This is a generic feature of new physics produced from massive new particles: the reconstructed parent mass is the resonant feature. By assuming that the signal is localised, one can use regions away from the signal to estimate the background. The LHCO provided one R&D dataset with labels and three black boxes to play with: one with an anomaly decaying into two two-pronged resonances, one without an anomaly, and one with an anomaly featuring two different decay modes (a dijet decay X → qq and a trijet decay X → gY, Y → qq). There are currently no dedicated searches for these signals in LHC data.
No labels
About 20 algorithms were deployed on the LHCO datasets, including supervised learning, unsupervised learning, weakly supervised learning and semi-supervised learning. Supervised learning is the most widely used method across science and industry, whereby each training example has a label: “background” or “signal”. For this challenge, the data do not have labels as we do not know exactly what we are looking for, and so strategies trained with labels from a different dataset often did not work well. By contrast, unsupervised learning generally tries to identify events that are rarely or never produced by the background; weakly supervised methods use some context from data to provide noisy labels; and semi-supervised methods use some simulation information in order to have a partial set of labels. Each method has its strengths and weaknesses, and multiple approaches are usually needed to achieve a broad coverage of possible signals.
The Dark Machines data challenge focused on developing algorithms broadly sensitive to non-resonant anomalies
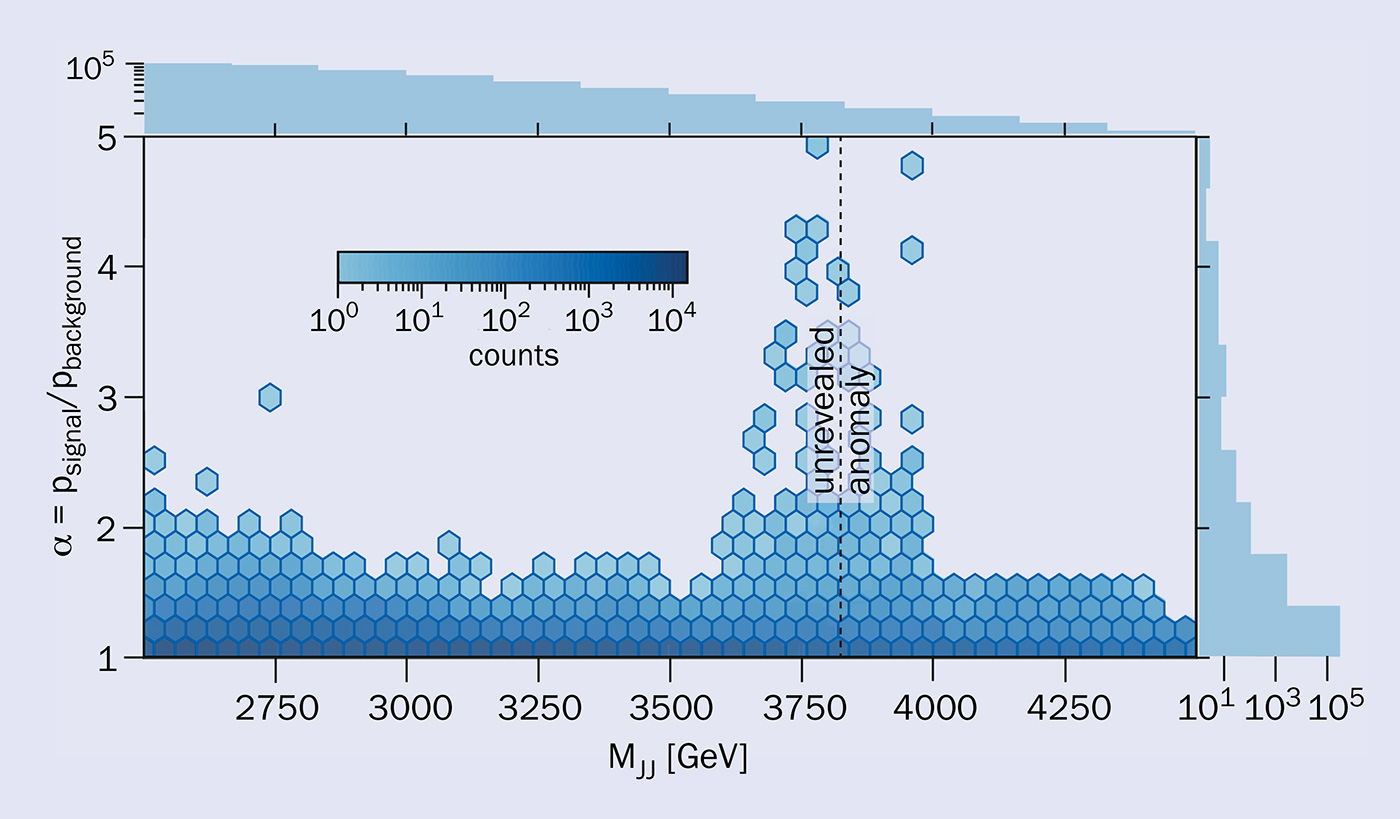
The best performance on the first black box in the LHCO challenge, as measured by finding and correctly characterising the anomalous signals, was by a team of cosmologists at Berkeley (George Stein, Uros Seljak and Biwei Dai) who compared the phase-space density between a sliding signal region and sidebands (see “Olympian algorithm” figure). Overall, the algorithms did well on the R&D dataset, and some also did well on the first black box, with methods that made use of likelihood ratios proving particularly effective. But no method was able to detect the anomalies in the third black box, and many teams reported a false signal for the second black box. This “placebo effect’’ illustrates the need for ML approaches to have an accurate estimation of the background and not just a procedure for identifying signals. The challenge for the third black box, however, required algorithms to identify multiple clusters of anomalous events rather than a single cluster. Future innovation is needed in this department.
Dark Machines
A second data challenge was launched in June 2020 within the Dark Machines initiative. Dark Machines is a research collective of physicists and data scientists who apply ML techniques to understand the nature of dark matter – as we don’t know the nature of dark matter, it is critical to search broadly for its anomalous signatures. The challenge was organised by Sascha Caron (Radboud University), Caterina Doglioni (University of Lund) and Maurizio Pierini (CERN), with notable contributions from Bryan Ostidiek (Harvard University) in the development of a common software infrastructure, and Melissa van Beekveld (University of Oxford) for dataset generation. In total, 39 participants arranged in 13 teams explored various unsupervised techniques, with each team submitting multiple algorithms.
By contrast with LHCO, the Dark Machines data challenge focused on developing algorithms broadly sensitive to non-resonant anomalies. Good examples of non-resonant new physics include many supersymmetric models and models of dark matter – anything where “invisible” particles don’t interact with the detector. In such a situation, resonant peaks become excesses in the tails of the missing-transverse-energy distribution. Two datasets were provided: R&D datasets including a concoction of SM processes and many signal samples for contestants to develop their approaches on; and a black-box dataset mixing SM events with events from unspecified signal processes. The challenge has now formally concluded, and its outcome was posted on arXiv in May, but the black-box has not been opened to allow the community to continue to test ideas on it.
A wide variety of unsupervised methods have been deployed so far. The algorithms use diverse representations of the collider events (for example, lists of particle four-momenta, or physics quantities computed from them), and both implicit and explicit approaches for estimating the probability density of the background (for example, autoencoders and “normalising flows”). While no single method universally achieved the highest sensitivity to new-physics events, methods that mapped the background to a fixed point and looked for events that were not described well by this mapping generally did better than techniques that had a so-called dynamic embedding. A key question exposed by this challenge that will inspire future innovation is how best to tune and combine unsupervised machine-learning algorithms in a way that is model independent with respect to the new physics describing the signal.
The enthusiastic response to the LHCO and Dark Machines data challenges highlights the important future role of unsupervised ML at the LHC and elsewhere in fundamental physics. So far, just one analysis has been published – a dijet-resonance search by the ATLAS collaboration using weakly-supervised ML – but many more are underway, and these techniques are even being considered for use in the level-one triggers of LHC experiments (see Hunting anomalies with an AI trigger). And as the detection of outliers also has a large number of real-world applications, from fraud detection to industrial maintenance, fruitful cross-talk between fundamental research and industry is possible.
The LHCO and Dark Machines data challenges are a stepping stone to an exciting experimental programme that is just beginning.
Further reading
T Aarrestad et al. 2021 arXiv:2105.14027.
ATLAS Collaboration 2020 Phys. Rev. Lett.25 131801.
G Kasieczka et al. 2021 arXiv:2101.08320.




