In Climate Change and Energy Options for a Sustainable Future, nuclear physicists Dinesh Kumar Srivastava and V S Ramamurthy explore global policies for an eco-friendly future. Facing the world’s increasing demand for energy, the authors argue for the replacement of fossil fuels with a new mixture of green energy sources including wind energy, solar photovoltaics, geothermal energy and nuclear energy. Srivastava is a theoretical physicist and Ramamurthy is an experimental physicist with research interests in heavy-ion physics and the quark–gluon plasma. Together, they analyse solutions offered by science and technology with a clarity that will likely surpass the expectations of non-expert readers. Following a pedagogical approach with vivid illustrations, the book offers an in-depth description of how each green-energy option could be integrated into a global-energy strategy.
In the first part of the book, the authors provide a wealth of evidence demonstrating the pressing reality of climate change and the fragility of the environment. Srivastava and Ramamurthy then examine unequal access to energy across the globe. There should be no doubt that human wellbeing is decided by the rate at which power is consumed, they write, and providing enough energy to everyone on the planet to reach a human-development index of 0.8, which is defined by the UN as high human development, calls for about 30 trillion kWh per year – roughly double the present global capacity.
Human wellbeing is decided by the rate at which power is consumed
Srivastava and Ramamurthy present the basic principles of alternative renewable sources, and offer many examples, including agrivoltaics in Africa, a floating solar-panel station in California and wind-turbines in the Netherlands and India. Drawing on their own expertise, they discuss nuclear energy and waste-management, accelerator-driven subcritical systems, and the use of high-current electron accelerators for water purification. The book then finally turns to sustainability, showing by means of a wealth of scientific data that increasing the supply of renewable energy, and reducing carbon-intensive energy sources, can lead to sustainable power across the globe, both reducing global-warming emissions and stabilising energy prices for a fairer economy. The authors stress that any solution should not compromise quality of life or development opportunities in developing countries.
This book could not be more timely. It is an invaluable resource for scientists, policymakers and educators.
Can we trust physics decisions made by machines? In recent applications of artificial intelligence (AI) to particle physics, we have partially sidestepped this question by using machine learning to augment analyses, rather than replace them. We have gained trust in AI decisions through careful studies of “control regions” and painstaking numerical simulations. As our physics ambitions grow, however, we are using “deeper” networks with more layers and more complicated architectures, which are difficult to validate in the traditional way. And to mitigate 10 to 100-fold increases in computing costs, we are planning to fully integrate AI into data collection, simulation and analysis at the high-luminosity LHC.
To build trust in AI, I believe we need to teach it to think like a physicist.
I am the director of the US National Science Foundation’s new Institute for Artificial Intelligence and Fundamental Interactions, which was founded last year. Our goal is to fuse advances in deep learning with time-tested strategies for “deep thinking” in the physical sciences. Many promising opportunities are open to us. Core principles of fundamental physics such as causality and spacetime symmetries can be directly incorporated into the structure of neural networks. Symbolic regression can often translate solutions learned by AI into compact, human-interpretable equations. In experimental physics, it is becoming possible to estimate and mitigate systematic uncertainties using AI, even when there are a large number of nuisance parameters. In theoretical physics, we are finding ways to merge AI with traditional numerical tools to satisfy stringent requirements that calculations be exact and reproducible. High-energy physicists are well positioned to develop trustworthy AI that can be scrutinised, verified and interpreted, since the five-sigma standard of discovery in our field necessitates it.
It is equally important, however, that we physicists teach ourselves how to think like a machine.
Modern AI tools yield results that are often surprisingly accurate and insightful, but sometimes unstable or biased. This can happen if the problem to be solved is “underspecified”, meaning that we have not provided the machine with a complete list of desired behaviours, such as insensitivity to noise, sensible ways to extrapolate and awareness of uncertainties. An even more challenging situation arises when the machine can identify multiple solutions to a problem, but lacks a guiding principle to decide which is most robust. By thinking like a machine, and recognising that modern AI solves problems through numerical optimisation, we can better understand the intrinsic limitations of training neural networks with finite and imperfect datasets, and develop improved optimisation strategies. By thinking like a machine, we can better translate first principles, best practices and domain knowledge from fundamental physics into the computational language of AI.
Beyond these innovations, which echo the logical and algorithmic AI that preceded the deep-learning revolution of the past decade, we are also finding surprising connections between thinking like a machine and thinking like a physicist. Recently, computer scientists and physicists have begun to discover that the apparent complexity of deep learning may mask an emergent simplicity. This idea is familiar from statistical physics, where the interactions of many atoms or molecules can often be summarised in terms of simpler emergent properties of materials. In the case of deep learning, as the width and depth of a neural network grows, its behaviour seems to be describable in terms of a small number of emergent parameters, sometimes just a handful. This suggests that tools from statistical physics and quantum field theory can be used to understand AI dynamics, and yield deeper insights into their power and limitations.
If we don’t exploit the full power of AI, we will not maximise the discovery potential of the LHC and other experiments
Ultimately, we need to merge the insights gained from artificial intelligence and physics intelligence. If we don’t exploit the full power of AI, we will not maximise the discovery potential of the LHC and other experiments. But if we don’t build trustable AI, we will lack scientific rigour. Machines may never think like human physicists, and human physicists will certainly never match the computational ability of AI, but together we have enormous potential to learn about the fundamental structure of the universe.
On 1 January, after a long struggle with a serious illness, Anatoly Vasilievich Efremov of the Bogoliubov Laboratory of Theoretical Physics (BLTP) at JINR, Dubna, Russia, passed away. He was an outstanding physicist, and a world expert in quantum field theory and elementary particle physics.
Anatoly Efremov was born in Kerch, Crimea, to the family of a naval officer. Since childhood, he retained his love for the sea and was an excellent yachtsman. After graduating from Moscow Engineering Physics Institute in 1958, where among his teachers were Isaak Pomeranchuk and his master’s thesis advisor Yakov Smorodinsky, he started working at BLTP JINR. At the time, Dmitrij Blokhintsev was JINR director. Anatoly always considered him as his teacher, as he did Dmitry Shirkov under whose supervision he defended his PhD thesis “Dispersion theory of low-energy scattering of pions” in 1962.
In 1971, Anatoly defended his DSc dissertation “High-energy asymptotics of Feynman diagrams”. The underlying work immediately found application in the factorisation of hard processes in quantum chromodynamics (QCD), which is now the theoretical basis of all hard-hadronic processes. Of particular note are his 1979 articles (written together with his PhD student A V Radyushkin) about the asymptotic behaviour of the pion form factor in QCD, and the evolution equation for hard exclusive processes, which became known as the ERBL (Efremov–Radyushkin–Brodsky–Lepage) equation. Proving the factorisation of hard processes enabled many subtle effects in QCD to be described, in particular parton correlations, which became known as the ETQS (Efremov–Teryaev–Qiu–Sterman) mechanism.
During the past three decades, Efremov, together with his students and colleagues, devoted his attention to several problems: the proton spin; the role of the axial anomaly and spin of gluons in the spin structure of a nucleon; correlations of the spin of partons; and momenta of particles in jets (“handedness”). These effects served as the theoretical basis for polarised particle experiments at RHIC at Brookhaven, the SPS at CERN and the new NICA facility at JINR. Anatoly was a member of the COMPASS collaboration at the SPS, where he helped to measure the effects he had predicted.
In 1976 he suggested the first model for the production of cumulative particles at x > 1 off nuclei. Within QCD, Efremov was the first to develop the concept of nuclear quark–parton structure function, which entails the presence in the nucleus of a hard collective quark sea. This naturally explains both the EMC nuclear effect and cumulative particle production, and unambiguously indicates the existence of multi- quark density fluctuations (fluctons) – a prediction that was later confirmed and led to the so-called nuclear super-scaling phenomenon. Today, similar effects of fluctons or short-range correlations are investigated in a fixed-target experiment at NICA and in several experiments at Jlab in the US.
Throughout his life, Anatoly continued to develop concrete manifestations of his ideas based on fundamental theory
Throughout his life, Anatoly continued to develop concrete manifestations of his ideas based on fundamental theory, becoming a teacher and advisor of many physicists at JINR, in Russia and abroad. In 1991 he initiated and became the permanent chair of the organising committee of the Dubna International Workshops on Spin Physics at High Energies. He was a long-term and authoritative member of the International Spin Physics Committee coordinating work in this area, and a regular visitor to the CERN theory unit since the 1970s.
Anatoly Vasilievich Efremov was the undisputed scientific leader, who initiated studies of quantum chromodynamics and spin physics in Dubna, one of the key BLTP JINR staff, and at the same time a modest and very friendly person, enjoying the highest authority and respect of colleagues. It is this combination of scientific and human qualities that made Anatoly Efremov’s personality unique, and this is how we will remember him.
This short film focuses on mechanic turned physicist Rana Adhikari, who contributed to the 2016 discovery of gravitational waves with the Laser Interferometer Gravitational-wave Observatory (LIGO). A laid-back, confident character, Adhikari takes us through the basics of LIGO, while touching upon the future of the field and the public’s view on fundamental research, all while directors Currimbhoy, McCarthy and Pedri facilitate the conversation, which runs at just over 12 minutes.
Following high-school, Adhikari spent time as a car mechanic. Upon reading Einstein’s Medium of Relativity during Hurricane Erin, however, he decided that he wanted to “test the speed of light.” Now, he is a professor at Caltech and a member of the LIGO collaboration, and was awarded a 2019 New Horizons in Physics Prize for his role in the gravitational-wave discovery.
In the film, recorded in 2018, Adhikari explains how fundamental research can be something everyone can get behind, in a world where it is “easy to think we’re all doomed,” and describes the power that rests on collaborations to show the importance of coming together, expressing, “It is a statement of collective willpower.” Through varying shots of him at a blackboard, in and around his experiment, and documentary-style face-to-face discussions, the audience quickly gets to know a positive thinker for whom work is clearly a passion, not a job.
The directors trust Adhikari to take centre stage and explain the world of gravitational waves through accurate metaphors that seem freestyled, yet concise. A sharp cut to a shot of turtles seems unnatural at first, before transforming into an analogy of Adhikari himself – the turtles going underwater and popping their heads up into different streams representing Adhikari’s curiosity, and how he got into the field in the first place.
The film is littered with references to music, most notably with comparisons between guitar strings and the vibrations that LIGO physicists are searching for. After playing a short, smooth riff, Adhikari states his unusual way of analysing data. “It is easier to do maths later – sometimes it’s better to just feel it.” He then plays us the “sound” file of two black holes colliding; a short chirp that is repeated as punchy statements about the long history of gravitational waves are overlayed onto the film.
We should be exploring fundamentals driven by curiosity
Towards the end, the focus takes a shift towards the public’s view on fundamental research. “Lasers weren’t created to scan items in supermarkets,” states Adhikari. “We should be exploring fundamentals driven by curiosity.” The film closes on Adhikari discussing the future of LIGO, tapping a glass to cause a lengthy ring representing the search for longer-wavelength gravitational waves.
Through Adhikari’s story, LIGO: The way the universe Is, I think will inspire anyone who feels alienated or intimidated by fundamental research.
Field lines arc through the air. By chance, a cosmic ray knocks an electron off a molecule. It hurtles away, crashing into other molecules and multiplying the effect. The temperature rises, liberating a new supply of electrons. A spark lights up the dark.
The absence of causal inference in practical machine learning touches on every aspect of AI research, application, ethics and policy
Vivienne Ming is a theoretical neuroscientist and a serial AI entrepreneur
This is an excellent metaphor for the Sparks! Serendipity Forum – a new annual event at CERN designed to encourage interdisciplinary collaborations between experts on key scientific issues of the day. The first edition, which will take place from 17 to 18 September, will focus on artificial intelligence (AI). Fifty leading thinkers will explore the future of AI in topical groups, with the outcomes of their exchanges to be written up and published in the journal Machine Learning: Science and Technology. The forum reflects the growing use of machine-learning techniques in particle physics and emphasises the importance that CERN and the wider community places on collaborating with diverse technological sectors. Such interactions are essential to the long-term success of the field.
AI is orders of magnitude faster than traditional numerical simulations. On the other side of the coin, simulations are being used to train AI in domains such as robotics where real data is very scarce
Anima Anandkumar is Bren professor at Caltech and director of machine learning research at NVIDIA
The likelihood of sparks flying depends on the weather. To take the temperature, CERN Courier spoke to a sample of the Sparks! participants to preview themes for the September event.
2020 revealed unexpectedly fragile technological and socio-cultural infrastructures. How we locate our conversations and research about AI in those contexts feels as important as the research itself
Genevieve Bell is director of the School of Cybernetics at the Australian National University and vice president at Intel
Back to the future
In the 1980s, AI research was dominated by code that emulated logical reasoning. In the 1990s and 2000s, attention turned to softening its strong syllogisms into probabilistic reasoning. Huge strides forward in the past decade have rejected logical reasoning, however, instead capitalising on computing power by letting layer upon layer of artificial neurons discern the relationships inherent in vast data sets. Such “deep learning” has been transformative, fuelling innumerable innovations, from self-driving cars to searches for exotica at the LHC (see Hunting anomalies with an AI trigger). But many Sparks! participants think that the time has come to reintegrate causal logic into AI.
Geneva is the home not only of CERN but also of the UN negotiations on lethal autonomous weapons. The major powers must put the evil genie back in the bottle before it’s too late
Stuart Russell is professor of computer science at the University of California, Berkeley and coauthor of the seminal text on AI
“A purely predictive system, such as the current machine learning that we have, that lacks a notion of causality, seems to be very severely limited in its ability to simulate the way that people think,” says Nobel-prize-winning cognitive psychologist Daniel Kahneman. “Current AI is built to solve one specific task, which usually does not include reasoning about that task,” agrees AAAI president-elect Francesca Rossi. “Leveraging what we know about how people reason and behave can help build more robust, adaptable and generalisable AI – and also AI that can support humans in making better decisions.”
AI is converging on forms of intelligence that are useful but very likely not human-like
Tomaso Poggio is a cofounder of computational neuroscience and Eugene McDermott professor at MIT
Google’s Nyalleng Moorosi identifies another weakness of deep-learning models that are trained with imperfect data: whether AI is deciding who deserves a loan or whether an event resembles physics beyond the Standard Model, its decisions are only as good as its training. “What we call the ground truth is actually a system that is full of errors,” she says.
We always had privacy violation, we had people being blamed falsely for crimes they didn’t do, we had mis-diagnostics, we also had false news, but what AI has done is amplify all this, and make it bigger
Nyalleng Moorosi is a research software engineer at Google and a founding member of Deep Learning Indaba
Furthermore, says influential computational neuroscientist Tomaso Poggio, we don’t yet understand the statistical behaviour of deep-learning algorithms with mathematical precision. “There is a risk in trying to understand things like particle physics using tools we don’t really understand,” he explains, also citing attempts to use artificial neural networks to model organic neural networks. “It seems a very ironic situation, and something that is not very scientific.”
This idea of partnership, that worries me. It looks to me like a very unstable equilibrium. If the AI is good enough to help the person, then pretty soon it will not need the person
Daniel Kahneman is a renowned cognitive psychologist and a winner of the 2002 Nobel Prize in Economics
Stuart Russell, one of the world’s most respected voices on AI, echoes Poggio’s concerns, and also calls for a greater focus on controlled experimentation in AI research itself. “Instead of trying to compete between Deep Mind and OpenAI on who can do the biggest demo, let’s try to answer scientific questions,” he says. “Let’s work the way scientists work.”
Good or bad?
Though most Sparks! participants firmly believe that AI benefits humanity, ethical concerns are uppermost in their minds. From social-media algorithms to autonomous weapons, current AI overwhelmingly lacks compassion and moral reasoning, is inflexible and unaware of its fallibility, and cannot explain its decisions. Fairness, inclusivity, accountability, social cohesion, security and international law are all impacted, deepening links between the ethical responsibilities of individuals, multinational corporations and governments. “This is where I appeal to the human-rights framework,” says philosopher S Matthew Liao. “There’s a basic minimum that we need to make sure everyone has access to. If we start from there, a lot of these problems become more tractable.”
We need to understand ethical principles, rather than just list them, because then there’s a worry that we’re just doing ethics washing – they sound good but they don’t have any bite
S Matthew Liao is a philosopher and the director of the Center for Bioethics at New York University
Far-term ethical considerations will be even more profound if AI develops human-level intelligence. When Sparks! participants were invited to put a confidence interval on when they expect human-level AI to emerge, answers ranged from [2050, 2100] at 90% confidence to [2040, ∞] at 99% confidence. Other participants said simply “in 100 years” or noted that this is “delightfully the wrong question” as it’s too human-centric. But by any estimation, talking about AI cannot wait.
Only a multi-stakeholder and multi-disciplinary approach can build an ecosystem of trust around AI. Education, cultural change, diversity and governance are equally as important as making AI explainable, robust and transparent
Francesca Rossi co-leads the World Economic Forum Council on AI for humanity and is IBM AI ethics global leader and the president-elect of AAAI
“With Sparks!, we plan to give a nudge to serendipity in interdisciplinary science by inviting experts from a range of fields to share their knowledge, their visions and their concerns for an area of common interest, first with each other, and then with the public,” says Joachim Mnich, CERN’s director for research and computing. “For the first edition of Sparks!, we’ve chosen the theme of AI, which is as important in particle physics as it is in society at large. Sparks! is a unique experiment in interdisciplinarity, which I hope will inspire continued innovative uses of AI in high-energy physics. I invite the whole community to get involved in the public event on 18 September.”
In the 1970s, the robust mathematical framework of the Standard Model (SM) replaced data observation as the dominant starting point for scientific inquiry in particle physics. Decades-long physics programmes were put together based on its predictions. Physicists built complex and highly successful experiments at particle colliders, culminating in the discovery of the Higgs boson at the LHC in 2012.
Along this journey, particle physicists adapted their methods to deal with ever growing data volumes and rates. To handle the large amount of data generated in collisions, they had to optimise real-time selection algorithms, or triggers. The field became an early adopter of artificial intelligence (AI) techniques, especially those falling under the umbrella of “supervised” machine learning. Verifying the SM’s predictions or exposing its shortcomings became the main goal of particle physics. But with the SM now apparently complete, and supervised studies incrementally excluding favoured models of new physics, “unsupervised” learning has the potential to lead the field into the uncharted waters beyond the SM.
Blind faith
To maximise discovery potential while minimising the risk of false discovery claims, physicists design rigorous data-analysis protocols to minimise the risk of human bias. Data analysis at the LHC is blind: physicists prevent themselves from combing through data in search of surprises. Simulations and “control regions” adjacent to the data of interest are instead used to design a measurement. When the solidity of the procedure is demonstrated, an internal review process gives the analysts the green light to look at the result on the real data and produce the experimental result.
A blind analysis is by necessity a supervised approach. The hypothesis being tested is specified upfront and tested against the null hypothesis – for example, the existence of the Higgs boson in a particular mass range versus its absence. Once spelled out, the hypothesis determines other aspects of the experimental process: how to select the data, how to separate signals from background and how to interpret the result. The analysis is supervised in the sense that humans identify what the possible signals and backgrounds are, and label examples of both for the algorithm.
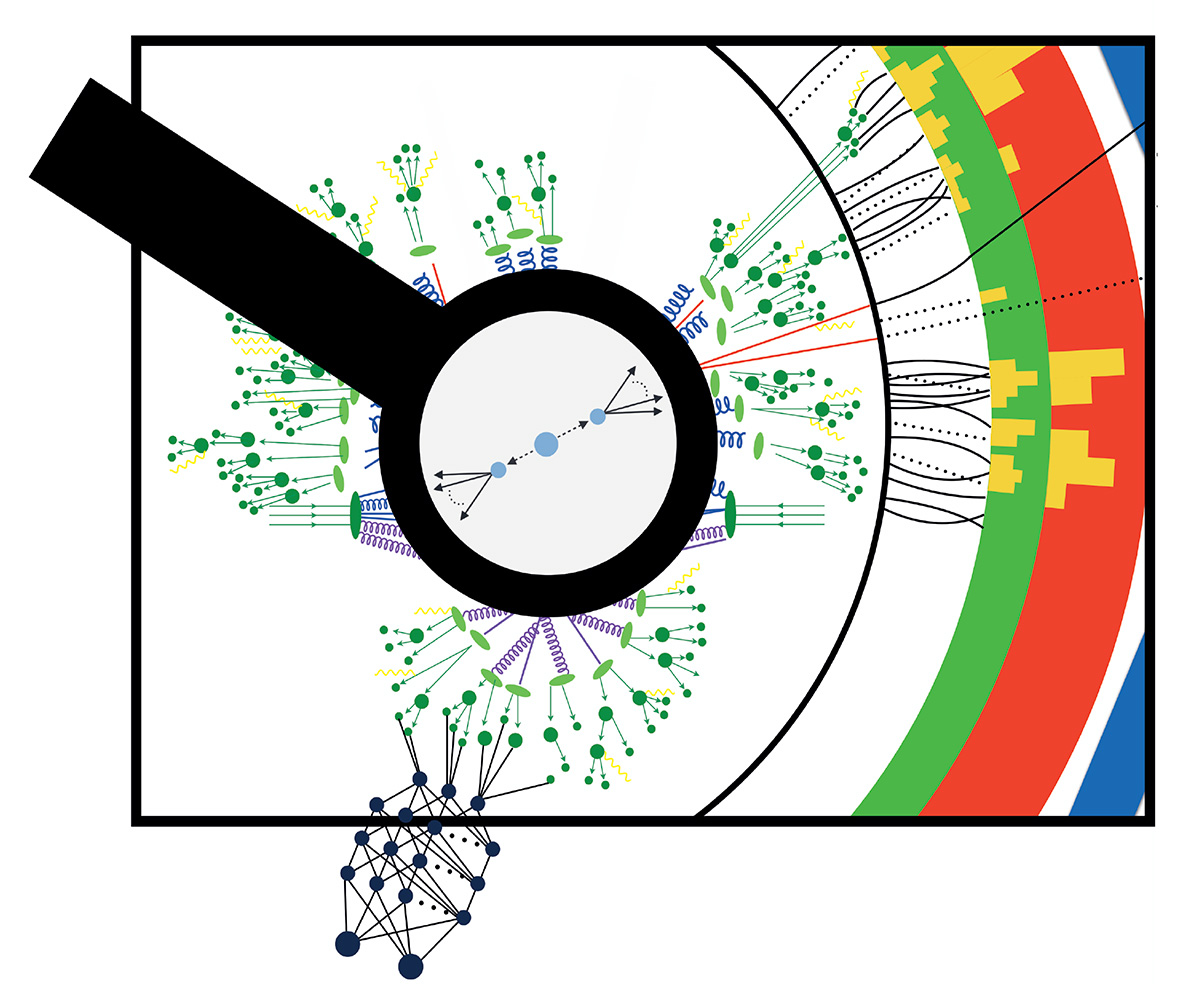
The data flow at the LHC makes the need to specify a signal hypothesis upfront even more compelling. The LHC produces 40 million collision events every second. Each overlaps with 34 others from the same bunch crossing, on average, like many pictures superimposed on top of each other. However, the computing infrastructure of a typical experiment is designed to sustain a data flow of just 1000 events per second. To avoid being overwhelmed by the data pressure, it’s necessary to select these 1000 out of every 40 million events in a short time. But how do you decide what’s interesting?
This is where the supervised nature of data analysis at the LHC comes into play. A set of selection rules – the trigger algorithms – are designed so that the kind of collisions predicted by the signal hypotheses being studied are present among the 1000 (see “Big data” figure). As long as you know what to look for, this strategy optimises your resources. The discovery in 2012 of the Higgs boson demonstrates this: a mission considered impossible in the 1980s was accomplished with less data and less time than anticipated by the most optimistic guesses when the LHC was being designed. Machine learning played a crucial role in this.
Machine learning
Machine learning (ML) is a branch of computer science that deals with algorithms capable of accomplishing a task without being explicitly programmed to do so. Unlike traditional algorithms, which are sets of pre-determined operations, an ML algorithm is not programmed. It is trained on data, so that it can adjust itself to maximise its chances of success, as defined by a quantitative figure of merit.
To explain further, let’s use the example of a dataset of images of cats and dogs. We’ll label the cats as “0” and the dogs as “1”, and represent the images as a two-dimensional array of coloured pixels, each with a fraction of red, green and blue. Each dog or cat is now a stack of three two-dimensional arrays of numbers between 0 and 1 – essentially just the animal pictured in red, green and blue light. We would like to have a mathematical function converting this stack of arrays into a score ranging from 0 to 1. The larger the score, the higher the probability that the image is a dog. The smaller the score, the higher the probability that the image is a cat. An ML algorithm is a function of this kind, whose parameters are fixed by looking at a given dataset for which the correct labels are known. Through a training process, the algorithm is tuned to minimise the number of wrong answers by comparing its prediction to the labels.
Now replace the dogs with photons from the decay of a Higgs boson, and the cats with detector noise that is mistaken to be photons. Repeat the procedure, and you will obtain a photon-identification algorithm that you can use on LHC data to improve the search for Higgs bosons. This is what happened in the CMS experiment back in 2012. Thanks to the use of a special kind of ML algorithm called boosted decision trees, it was possible to maximise the accuracy of the Higgs-boson search, exploiting the rich information provided by the experiment’s electromagnetic calorimeter. The ATLAS collaboration developed a similar procedure to identify Higgs bosons decaying into a pair of tau leptons.
Photon and tau-lepton classifiers are both examples of supervised learning, and the success of the discovery of the Higgs boson was also a success story for applied ML. So far so good. But what about searching for new physics?
Typical examples of new physics such as supersymmetry, extra dimensions and the underlying structure for the Higgs boson have been extensively investigated at the LHC, with no evidence for them found in data. This has told us a great deal about what the particles predicted by these scenarios cannot look like, but what if the signal hypotheses are simply wrong, and we’re not looking for the right thing? This situation calls for “unsupervised” learning, where humans are not required to label data. As with supervised learning, this idea doesn’t originate in physics. Marketing teams use clustering algorithms based on it to identify customer segments. Banks use it to detect credit-card fraud by looking for anomalous access patterns in customers’ accounts. Similar anomaly detection techniques could be used at the LHC to single out rare events, possibly originating from new, previously undreamt of, mechanisms.
Unsupervised learning
Anomaly detection is a possible strategy for keeping watch for new physics without having to specify an exact signal. A kind of unsupervised ML, it involves ranking an unlabelled dataset from the most typical to the most atypical, using a ranking metric learned during training. One of the advantages of this approach is that the algorithm can be trained on data recorded by the experiment rather than simulations. This could, for example, be a control sample that we know to be dominated by SM processes: the algorithm will learn how to reconstruct these events “exactly” – and conversely how to rank unknown processes as atypical. As a proof of principle, this strategy has already been applied to re-discover the top quark using the first open-data release by the CMS collaboration.
This approach could be used in the online data processing at the LHC and applied to the full 40 million collision events produced every second. Clustering techniques commonly used in observational astronomy could be used to highlight the recurrence of special kinds of events.
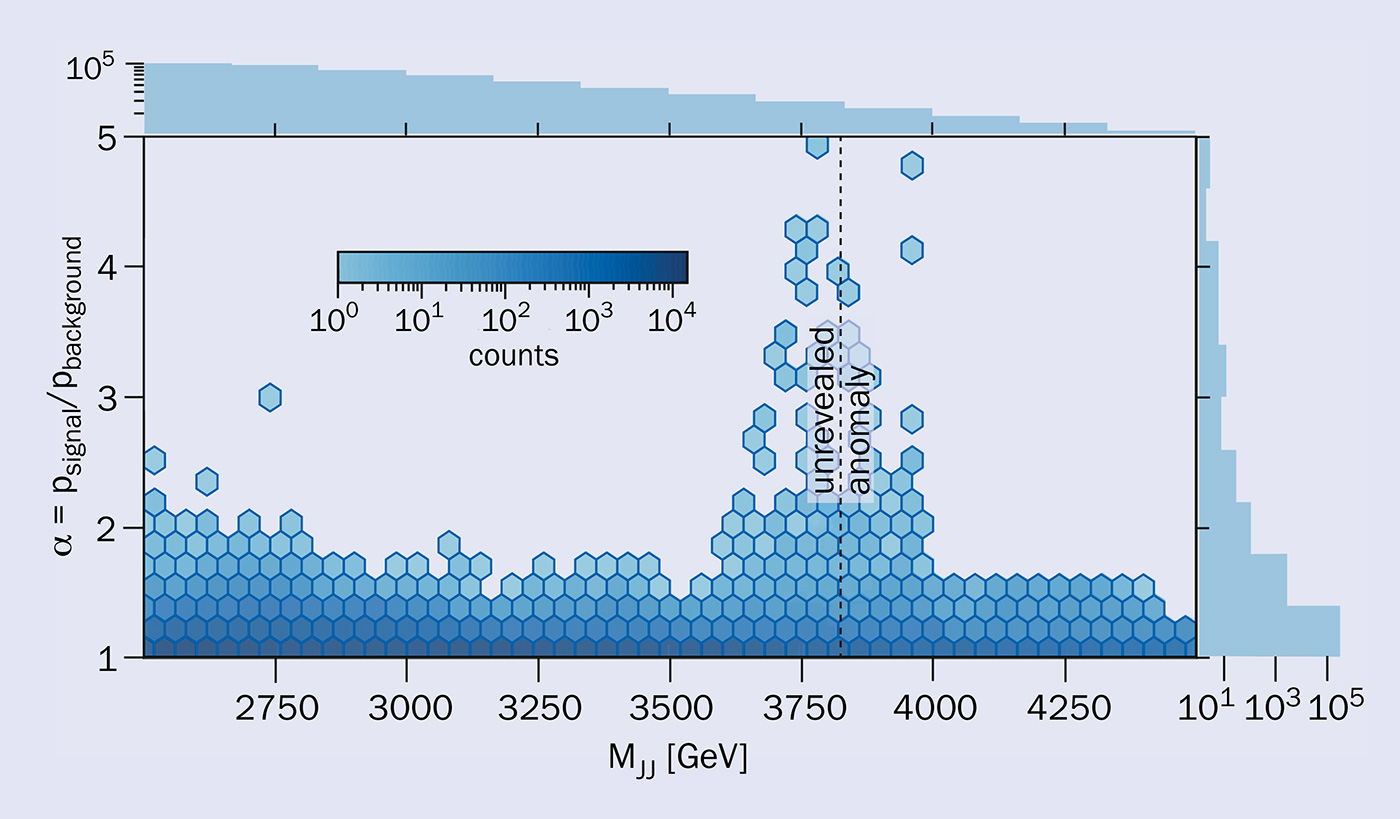
In case a new kind of process happens in an LHC collision, but is discarded by the trigger algorithms serving the traditional physics programme, an anomaly-detection algorithm could save the relevant events, storing them in a special stream of anomalous events (see “Anomaly hunting” figure). The ultimate goal of this approach would be the creation of an “anomaly catalogue” of event topologies for further studies, which could inspire novel ideas for new-physics scenarios to test using more traditional techniques. With an anomaly catalogue, we could return to the first stage of the scientific method, and recover a data-driven alternative approach to the theory-driven investigation that we have come to rely on.
This idea comes with severe technological challenges. To apply this technique to all collision events, we would need to integrate the algorithm, typically a special kind of neural network called an autoencoder, into the very first stage of the online data selection, the level-one (L1) trigger. The L1 trigger consists of logic algorithms integrated onto custom electronic boards based on field programmable gate arrays (FPGAs) – a highly parallelisable chip that serves as a programmable emulator of electronic circuits. Any L1 trigger algorithm has to run within the order of one microsecond, and take only a fraction of the available computing resources. To run in the L1 trigger system, an anomaly detection network needs to be converted into an electronic circuit that would fulfill these constraints. This goal can be met using the “hls4ml” (high-level synthesis for ML) library – a tool designed by an international collaboration of LHC physicists that exploits automatic workflows.
Computer-science collaboration
Recently, we collaborated with a team of researchers from Google to integrate the hls4ml library into Google’s “QKeras” – a tool for developing accurate ML models on FPGAs with a limited computing footprint. Thanks to this partnership, we developed a workflow that can design a ML model in concert with its final implementation on the experimental hardware. The resulting QKeras+hls4ml bundle is designed to allow LHC physicists to deploy anomaly-detection algorithms in the L1 trigger system. This approach could practically be deployed in L1 trigger systems before the end of LHC Run 3 – a powerful complement to the anomaly-detection techniques that are already being considered for “offline” data analysis on the traditionally triggered samples.
AI techniques could help the field break beyond the limits of human creativity in theory building
If this strategy is endorsed by the experimental collaborations, it could create a public dataset of anomalous data that could be investigated during the third LHC long shutdown, from 2025 to 2027. By studying those events, phenomenologists and theoretical physicists could formulate creative hypotheses about new-physics scenarios to test, potentially opening up new search directions for the High-Luminosity LHC.
Blind analyses minimise human bias if you know what to look for, but risk yielding diminishing returns when the theoretical picture is uncertain, as is the case in particle physics after the first 10 years of LHC physics. Unsupervised AI techniques such as anomaly detection could help the field break beyond the limits of human creativity in theory building. In the big-data environment of the LHC, they offer a powerful means to move the field back to data-driven discovery, after 50 years of theory-driven progress. To maximise their impact, they should be applied to every collision produced at the LHC. For that reason, we argue that anomaly-detection algorithms should be deployed in the L1 triggers of the LHC experiments, despite the technological challenges that must be overcome to make that happen.
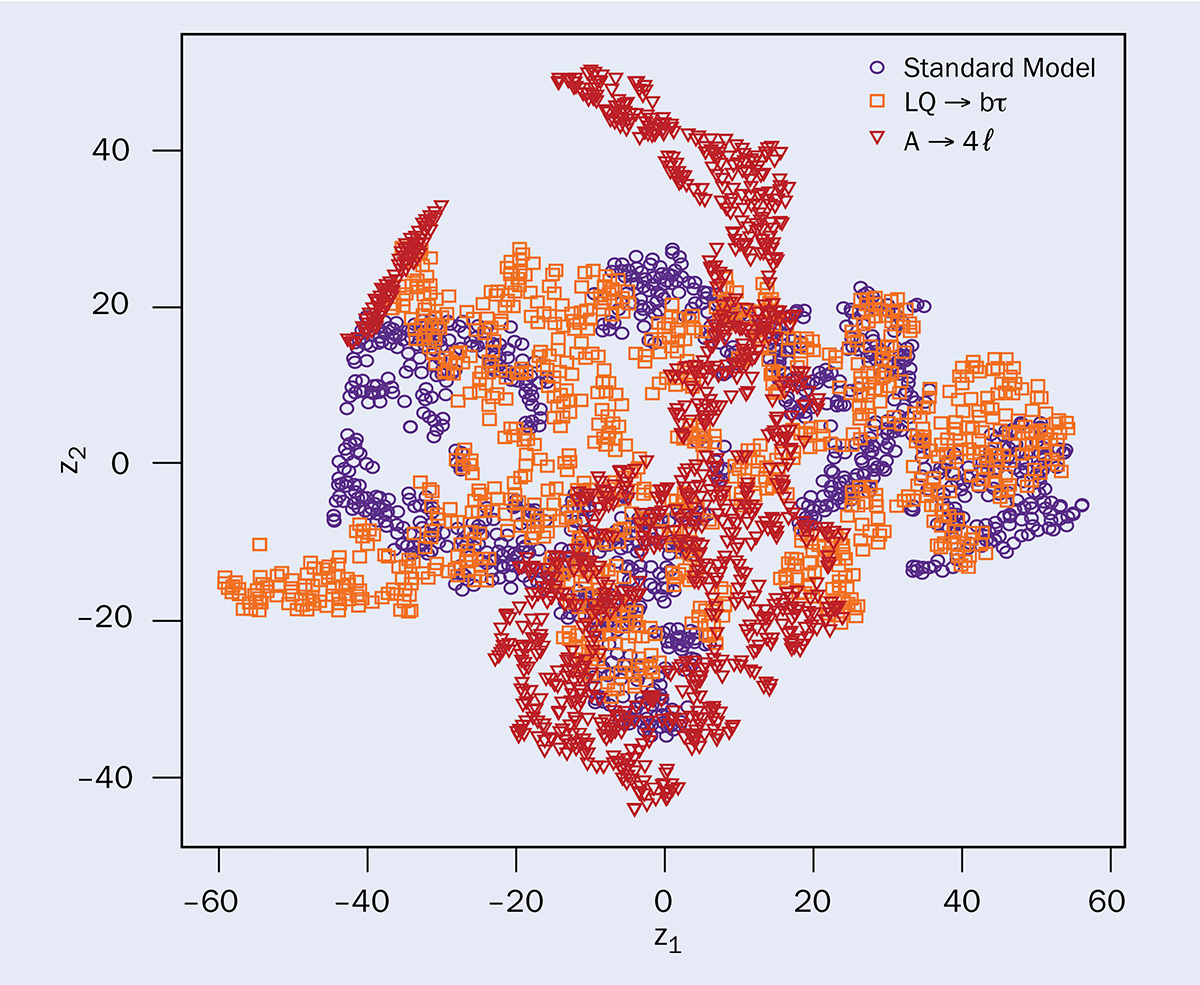
The need for innovation in machine learning (ML) transcends any single experimental collaboration, and requires more in-depth work than can take place at a workshop. Data challenges, wherein simulated “black box” datasets are made public, and contestants design algorithms to analyse them, have become essential tools to spark interdisciplinary collaboration and innovation. Two have recently concluded. In both cases, contestants were challenged to use ML to figure out “what’s in the box?”
LHC Olympics
The LHC Olympics (LHCO) data challenge was launched in autumn 2019, and the results were presented at the ML4Jets and Anomaly Detection workshops in spring and summer 2020. A final report summarising the challenge was posted to arXiv earlier this year, written by around 50 authors from a variety of backgrounds in theory, the ATLAS and CMS experiments, and beyond. The name of this community effort was inspired by the first LHC Olympics that took place more than a decade ago, before the start of the LHC. In those olympics, researchers were worried about being able to categorise all of the new particles that would be discovered when the machine turned on. Since then, we have learned a great deal about nature at TeV energy scales, with no evidence yet for new particles or forces of nature. The latest LHC Olympics focused on a different challenge – being able to find new physics in the first place. We now know that new physics must be rare and not exactly like what we expected.
In order to prepare for rare and unexpected new physics, organisers Gregor Kasieczka (University of Hamburg), Benjamin Nachman (Lawrence Berkeley National Laboratory) and David Shih (Rutgers University) provided a set of black-box datasets composed mostly of Standard Model (SM) background events. Contestants were charged with identifying any anomalous events that would be a sign of new physics. These datasets focused on resonant anomaly detection, whereby the anomaly is assumed to be localised – a “bump hunt”, in effect. This is a generic feature of new physics produced from massive new particles: the reconstructed parent mass is the resonant feature. By assuming that the signal is localised, one can use regions away from the signal to estimate the background. The LHCO provided one R&D dataset with labels and three black boxes to play with: one with an anomaly decaying into two two-pronged resonances, one without an anomaly, and one with an anomaly featuring two different decay modes (a dijet decay X → qq and a trijet decay X → gY, Y → qq).There are currently no dedicated searches for these signals in LHC data.
No labels
About 20 algorithms were deployed on the LHCO datasets, including supervised learning, unsupervised learning, weakly supervised learning and semi-supervised learning. Supervised learning is the most widely used method across science and industry, whereby each training example has a label: “background” or “signal”. For this challenge, the data do not have labels as we do not know exactly what we are looking for, and so strategies trained with labels from a different dataset often did not work well. By contrast, unsupervised learning generally tries to identify events that are rarely or never produced by the background; weakly supervised methods use some context from data to provide noisy labels; and semi-supervised methods use some simulation information in order to have a partial set of labels. Each method has its strengths and weaknesses, and multiple approaches are usually needed to achieve a broad coverage of possible signals.
The Dark Machines data challenge focused on developing algorithms broadly sensitive to non-resonant anomalies
The best performance on the first black box in the LHCO challenge, as measured by finding and correctly characterising the anomalous signals, was by a team of cosmologists at Berkeley (George Stein, Uros Seljak and Biwei Dai) who compared the phase-space density between a sliding signal region and sidebands (see “Olympian algorithm” figure). Overall, the algorithms did well on the R&D dataset, and some also did well on the first black box, with methods that made use of likelihood ratios proving particularly effective. But no method was able to detect the anomalies in the third black box, and many teams reported a false signal for the second black box. This “placebo effect’’ illustrates the need for ML approaches to have an accurate estimation of the background and not just a procedure for identifying signals. The challenge for the third black box, however, required algorithms to identify multiple clusters of anomalous events rather than a single cluster. Future innovation is needed in this department.
Dark Machines
A second data challenge was launched in June 2020 within the Dark Machines initiative. Dark Machines is a research collective of physicists and data scientists who apply ML techniques to understand the nature of dark matter – as we don’t know the nature of dark matter, it is critical to search broadly for its anomalous signatures. The challenge was organised by Sascha Caron (Radboud University), Caterina Doglioni (University of Lund) and Maurizio Pierini (CERN), with notable contributions from Bryan Ostidiek (Harvard University) in the development of a common software infrastructure, and Melissa van Beekveld (University of Oxford) for dataset generation. In total, 39 participants arranged in 13 teams explored various unsupervised techniques, with each team submitting multiple algorithms.
By contrast with LHCO, the Dark Machines data challenge focused on developing algorithms broadly sensitive to non-resonant anomalies. Good examples of non-resonant new physics include many supersymmetric models and models of dark matter – anything where “invisible” particles don’t interact with the detector. In such a situation, resonant peaks become excesses in the tails of the missing-transverse-energy distribution. Two datasets were provided: R&D datasets including a concoction of SM processes and many signal samples for contestants to develop their approaches on; and a black-box dataset mixing SM events with events from unspecified signal processes. The challenge has now formally concluded, and its outcome was posted on arXiv in May, but the black-box has not been opened to allow the community to continue to test ideas on it.
A wide variety of unsupervised methods have been deployed so far. The algorithms use diverse representations of the collider events (for example, lists of particle four-momenta, or physics quantities computed from them), and both implicit and explicit approaches for estimating the probability density of the background (for example, autoencoders and “normalising flows”). While no single method universally achieved the highest sensitivity to new-physics events, methods that mapped the background to a fixed point and looked for events that were not described well by this mapping generally did better than techniques that had a so-called dynamic embedding. A key question exposed by this challenge that will inspire future innovation is how best to tune and combine unsupervised machine-learning algorithms in a way that is model independent with respect to the new physics describing the signal.
The enthusiastic response to the LHCO and Dark Machines data challenges highlights the important future role of unsupervised ML at the LHC and elsewhere in fundamental physics. So far, just one analysis has been published – a dijet-resonance search by the ATLAS collaboration using weakly-supervised ML – but many more are underway, and these techniques are even being considered for use in the level-one triggers of LHC experiments (see Hunting anomalies with an AI trigger). And as the detection of outliers also has a large number of real-world applications, from fraud detection to industrial maintenance, fruitful cross-talk between fundamental research and industry is possible.
The LHCO and Dark Machines data challenges are a stepping stone to an exciting experimental programme that is just beginning.
How might artificial intelligence make an impact on theoretical physics?
John Ellis (JE): To phrase it simply: where do we go next? We have the Standard Model, which describes all the visible matter in the universe successfully, but we know dark matter must be out there. There are also puzzles, such as what is the origin of the matter in the universe? During my lifetime we’ve been playing around with a bunch of ideas for tackling those problems, but haven’t come up with solutions. We have been able to solve some but not others. Could artificial intelligence (AI) help us find new paths towards attacking these questions? This would be truly stealing theoretical physicists’ lunch.
Anima Anandkumar (AA): I think the first steps are whether you can understand more basic physics and be able to come up with predictions as well. For example, could AI rediscover the Standard Model? One day we can hope to look at what the discrepancies are for the current model, and hopefully come up with better suggestions.
JE: An interesting exercise might be to take some of the puzzles we have at the moment and somehow equip an AI system with a theoretical framework that we physicists are trying to work with, let the AI loose and see whether it comes up with anything. Even over the last few weeks, a couple of experimental puzzles have been reinforced by new results on B-meson decays and the anomalous magnetic moment of the muon. There are many theoretical ideas for solving these puzzles but none of them strike me as being particularly satisfactory in the sense of indicating a clear path towards the next synthesis beyond the Standard Model. Is it imaginable that one could devise an AI system that, if you gave it a set of concepts that we have, and the experimental anomalies that we have, then the AI could point the way?
AA: The devil is in the details. How do we give the right kind of data and knowledge about physics? How do we express those anomalies while at the same time making sure that we don’t bias the model? There are anomalies suggesting that the current model is not complete – if you are giving that prior knowledge then you could be biasing the models away from discovering new aspects. So, I think that delicate balance is the main challenge.
JE: I think that theoretical physicists could propose a framework with boundaries that AI could explore. We could tell you what sort of particles are allowed, what sort of interactions those could have and what would still be a well-behaved theory from the point of view of relativity and quantum mechanics. Then, let’s just release the AI to see whether it can come up with a combination of particles and interactions that could solve our problems. I think that in this sort of problem space, the creativity would come in the testing of the theory. The AI might find a particle and a set of interactions that would deal with the anomalies that I was talking about, but how do we know what’s the right theory? We have to propose some other experiments that might test it – and that’s one place where the creativity of theoretical physicists will come into play.
AA: Absolutely. And many theories are not directly testable. That’s where the deeper knowledge and intuition that theoretical physicists have is so critical.
Is human creativity driven by our consciousness, or can contemporary AI be creative?
AA: Humans are creative in so many ways. We can dream, we can hallucinate, we can create – so how do we build those capabilities into AI? Richard Feynman famously said “What I cannot create, I do not understand.” It appears that our creativity gives us the ability to understand the complex inner workings of the universe. With the current AI paradigm this is very difficult. Current AI is geared towards scenarios where the training and testing distributions are similar, however, creativity requires extrapolation – being able to imagine entirely new scenarios. So extrapolation is an essential aspect. Can you go from what you have learned and extrapolate new scenarios? For that we need some form of invariance or understanding of the underlying laws. That’s where physics is front and centre. Humans have intuitive notions of physics from early childhood. We slowly pick them up from physical interactions with the world. That understanding is at the heart of getting AI to be creative.
JE: It is often said that a child learns more laws of physics than an adult ever will! As a human being, I think that I think. I think that I understand. How can we introduce those things into AI?
Could AI rediscover the Standard Model?
AA: We need to get AI to create images, and other kinds of data it experiences, and then reason about the likelihood of the samples. Is this data point unlikely versus another one? Similarly to what we see in the brain, we recently built feedback mechanisms into AI systems. When you are watching me, it’s not just a free-flowing system going from the retina into the brain; there’s also a feedback system going from the inferior temporal cortex back into the visual cortex. This kind of feedback is fundamental to us being conscious. Building these kinds of mechanisms into AI is the first step to creating conscious AI.
JE: A lot of the things that you just mentioned sound like they’re going to be incredibly useful going forward in our systems for analysing data. But how is AI going to devise an experiment that we should do? Or how is AI going to devise a theory that we should test?
AA: Those are the challenging aspects for an AI. A data-driven method using a standard neural network would perform really poorly. It will only think of the data that it can see and not about data that it hasn’t seen – what we call “zero-short generalisation”. To me, the past decade’s impressive progress is due to a trinity of data, neural networks and computing infrastructure, mainly powered by GPUs [graphics processing units], coming together: the next step for AI is a wider generalisation to the ability to extrapolate and predict hitherto unseen scenarios.
Across the many tens of orders of magnitude described by modern physics, new laws and behaviours “emerge” non-trivially in complexity (see Emergence). Could intelligence also be an emergent phenomenon?
JE: As a theoretical physicist, my main field of interest is the fundamental building blocks of matter, and the roles that they play very early in the history of the universe. Emergence is the word that we use when we try to capture what happens when you put many of these fundamental constituents together, and they behave in a way that you could often not anticipate if you just looked at the fundamental laws of physics. One of the interesting developments in physics over the past generation is to recognise that there are some universal patterns that emerge. I’m thinking, for example, of phase transitions that look universal, even though the underlying systems are extremely different. So, I wonder, is there something similar in the field of intelligence? For example, the brain structure of the octopus is very different from that of a human, so to what extent does the octopus think in the same way that we do?
AA: There’s a lot of interest now in studying the octopus. From what I learned, its intelligence is spread out so that it’s not just in its brain but also in its tentacles. Consequently, you have this distributed notion of intelligence that still works very well. It can be extremely camouflaged – imagine being in a wild ocean without a shell to protect yourself. That pressure created the need for intelligence such that it can be extremely aware of its surroundings and able to quickly camouflage itself or manipulate different tools.
JE: If intelligence is the way that a living thing deals with threats and feeds itself, should we apply the same evolutionary pressure to AI systems? We threaten them and only the fittest will survive. We tell them they have to go and find their own electricity or silicon or something like that – I understand that there are some first steps in this direction, computer programs competing with each other at chess, for example, or robots that have to find wall sockets and plug themselves in. Is this something that one could generalise? And then intelligence could emerge in a way that we hadn’t imagined?
Similarly to what we see in the brain, we recently built feedback mechanisms into AI systems
AA: That’s an excellent point. Because what you mentioned broadly is competition – different kinds of pressures that drive towards good, robust objectives. An example is generative adversarial models, which can generate very realistic looking images. Here you have a discriminator that challenges the generator to generate images that look real. These kinds of competitions or games are getting a lot of traction and we have now passed the Turing test when it comes to generating human faces – you can no longer tell very easily whether it is generated by AI or if it is a real person. So, I think those kinds of mechanisms that have competition built into the objective they optimise are fundamental to creating more robust and more intelligent systems.
JE: All this is very impressive – but there are still some elements that I am missing, which seem very important to theoretical physics. Take chess: a very big system but finite nevertheless. In some sense, what I try to do as a theoretical physicist has no boundaries. In some sense, it is infinite. So, is there any hope that AI would eventually be able to deal with problems that have no boundaries?
AA: That’s the difficulty. These are infinite-dimensional spaces… so how do we decide how to move around there? What distinguishes an expert like you from an average human is that you build your knowledge and develop intuition – you can quickly make judgments and find which narrow part of the space you want to work on compared to all the possibilities. That’s the aspect that is so difficult for AI to figure out. The space is enormous. On the other hand, AI does have a lot more memory, a lot more computational capacity. So can we create a hybrid system, with physicists and machine learning in tandem, to help us harness the capabilities of both AI and humans together? We’re currently exploring theorem provers: can we use the theorems that humans have proven, and then add reinforcement learning on top to create very fast theorem solvers? If we can create such fast theorem provers in pure mathematics, I can see them being very useful for understanding the Standard Model and the gaps and discrepancies in it. It is much harder than chess, for example, but there are exciting programming frameworks and data sets available, with efforts to bring together different branches of mathematics. But I don’t think humans will be out of the loop, at least for now.
“Our job is to be part of the scientific community and show that there can be religious people and priests who are scientists,” says Gabriele Gionti, a Roman Catholic priest and theoretical physicist specialising in quantum gravity who is resident at the Vatican Observatory.
“Our mission is to do good science,” agrees Guy Consolmagno, a noted planetary scientist, Jesuit brother and the observatory’s director. “I like to say we are missionaries of science to the believers.”
Not only missionaries of faith, then, but also of science. And there are advantages.
“At the Vatican Observatory, we don’t have to write proposals, we don’t have to worry about tenure and we don’t have to have results in three years to get our money renewed,” says Consolmagno, who is directly appointed by the Pope. “It changes the nature of the research that is available to us.”
“Here I have had time to just study,” says Gionti, who explains that he was able to extend his research to string theory as a result of this extra freedom. “If you are a postdoc or under tenure, you don’t have this opportunity.”
“I remember telling a friend of mine that I don’t have to write grant proposals, and he said, ‘how do I get in on this?’” jokes Consolmagno, a native of Detroit. “I said that he needed to take a vow of celibacy. He replied, ‘it’s worth it!’.”
Cannonball moment
Clad in T-shirts, Gionti and Consolmagno don’t resemble the priests and monks seen in movies. They are connected to monastic tradition, but do not withdraw from the world. As well as being full-time physicists, both are members of the Society of Jesus – a religious order that traces its origin to 1521, when Saint Ignatius of Loyola was struck in the leg by a cannonball at the Battle of Pamplona. Today they help staff at an institution that was founded in 1891, though its origins arguably date back to attempts to fix the date for Easter in 1582.
“It was at the end of the 19th century that the myth began that the church was anti-science, and they would use Galileo as the excuse,” says Consolmagno, explaining that the Pope at the time, Pope Leo XIII, wanted to demonstrate that faith and science were fully compatible. “The first thing that the Vatican Observatory did was to take part in the Carte du Ciel programme,” he says, hinting at a secondary motivation. “Every national observatory was given a region of the sky. Italy was given one region and the Vatican was given another. So, de facto, the Vatican became seen as an independent nation state.”
The observatory quickly established itself as a respected scientific organisation. Though it is staffed by priests and brothers, there is an absolute rule that science comes first, says Consolmagno, and the stereotypical work of a priest or monk is actually a temptation to be resisted. “Day-to-day life as a scientist can be tedious, and it can be a long time until you see a reward, but pastoral life can be rewarding immediately,” he explains.
Consolmagno was a planetary scientist for 20 years before becoming a Jesuit. By contrast, Gionti, who hails from Capua in Italy, joined after his first postdoc at UC Irvine in California. Neither reports encountering professional prejudice as a result of their vocation. “I think that’s a generational thing,” says Consolmagno. “Scientists working in the 1970s and 1980s were more likely to be anti-religious, but nowadays it’s not the case. You are looked on as part of the multicultural nature of the field.”
And besides, antagonism between science and religion is largely based on a false dichotomy, says Consolmagno. “The God that many atheists don’t believe in is a God that we also don’t believe in.”
The observatory’s director pushes back hard on the idea that faith is incompatible with physics. “It doesn’t tell me what science to do. It doesn’t tell me what the questions and answers are going to be. It gives me faith that I can understand the universe using reason and logic.”
Surprised by CERN
Due to light pollution in Castel Gandolfo, a new outpost of the Vatican Observatory was established in Tucson, Arizona, in 1980. A little later in the day, when the Sun was rising there, I spoke to Paul Gabor – an astrophysicist, Jesuit priest and deputy director for the Tucson observatory. Born in Košice, Slovakia, Gabor was a summer student at CERN in 1992, working on the development of the electromagnetic calorimeter of the ATLAS experiment, a project he later continued in Grenoble, thanks to winning a scholarship at the university. “We were making prototypes and models and software. We tested the actual physical models in a couple of test-beam runs – that was fun,” he recalls.
Gabor was surprised at how he found the laboratory. “It was an important part of my journey, because I was quite surprised that I found CERN to be full of extremely nice people. I was expecting everyone to be driven, ambitious, competitive and not necessarily collaborative, but people were very open,” he says. “It was a really good human experience for me.”
“When I finally caved in and joined the Jesuit order in 1995, I always thought, well, these scientists definitely are a group that I got to know and love, and I would like to, in one way or another, be a minister to them and be involved with them in some way.”
“Something that I came to realise, in a beginning, burgeoning kind of way at CERN, is the idea of science being a spiritual journey. It forms your personality and your soul in a way that any sustained effort does.”
Scientific athletes
“Experimental science can be a journey to wisdom,” says Gabor. “We are subject to constant frustration, failure and errors. We are confronted with our limitations. This is something that scientists have in common with athletes, for example. These long labours tend to make us grow as human beings. I think this point is quite important. In a way it explains my experience at CERN as a place full of nice, generous people.”
Surprisingly, however, despite being happy with life as a scientific religious and religious scientist, Gabor is not recruiting.
“There is a certain tendency to abandon science to join the priesthood or religious life,” he says. “This is not necessarily the best thing to do, so I urge a little bit of restraint. Religious zeal is a great thing, but if you are in the third year of a doctorate, don’t just pack up your bags and join a seminary. That is not a very prudent thing to do. That is to nobody’s benefit. This is a scenario that is all too common unfortunately.”
Consolmagno also offers words of caution. “50% of Jesuits leave the order,” he notes. “But this is a sign of success. You need to be where you belong.”
But Gionti, Consolmagno and Gabor all agree that, if properly discerned, the life of a scientific religious is a rewarding one in a community like the Vatican Observatory. They describe a close-knit group with a common purpose and little superficiality.
“Faith gives us the belief that the universe is good and worth studying,” says Consolmagno. “If you believe that the universe is good, then you are justified in spending your life studying things like quarks, even if it is not useful. Believing in God gives you a reason to study science for the sake of science.”
In a significant technological advance for antimatter research, the BASE (Baryon Antibaryon Symmetry Experiment) collaboration has used laser-cooled ions to cool a proton more quickly and to lower temperatures than is possible using existing methods. The new technique, which introduces a separate Penning trap, promises to reduce the time needed to cool protons and antiprotons to sub-Kelvin temperatures from hours to seconds, potentially increasing the sample sizes available for precision matter-antimatter comparisons by orders of magnitude. As reported today in Nature, the collaboration’s test setup at the University of Mainz also reached temperatures approximately 10 times lower than the limit of the established resistive-cooling technique.
“The factor 10 reduction in temperature which has been achieved in our paper is just a first step,” says BASE deputy spokesperson Christian Smorra of the University of Mainz and RIKEN. “With optimised procedures we should be able to reach particle temperatures of order 20 mK to 50 mK, ideally in cooling times of order 10 seconds. Previous methods allowed us to reach 100 mK in 10 hours.”
The new setup consists of two Penning traps separated by 9 cm. One trap contains a single proton. The other contains a cloud of beryllium ions that are laser-cooled using conventional techniques. The proton is cooled as its kinetic energy is transferred through a superconducting resonant electric circuit into the cooler beryllium trap.
The proton and the beryllium ions can be thought of as mechanical oscillators within the magnetic and electric fields of the Penning traps, explains lead author Matthew Bohman of the Max Planck Institute for Nuclear Physics in Heidelberg and RIKEN. “The resonant electric circuit acts like a spring, coupling the oscillations — the oscillation of the proton is damped by its coupling to the conventionally cooled cloud of beryllium ions.”
The collaboration’s unique two-trap sympathetic-cooling technique was first proposed in 1990 by Daniel Heinzen and David Wineland. Wineland went on to share the 2012 Nobel prize in physics for related work in manipulating individual particles while preserving quantum information. The use of a resonant electric circuit to couple the two Penning traps is an innovation by the BASE collaboration which speeds up the rate of energy exchange relative to Heinzen and Wineland’s proposal from minutes to seconds. The technique is useful for protons, but game-changing for antiprotons.
Antiproton prospects
A two-trap setup is attractive for antimatter because a single Penning trap cannot easily accommodate particles with opposite charges, and laser-cooled ions are nearly always positively charged, with electrons stripped away. BASE previously cooled antiprotons by coupling them to a superconducting resonator at around 4 K, and painstakingly selecting the lowest energy antiprotons in the ensemble over many hours.
Our technique shows that you can apply the laser-physics toolkit to exotic particles
Matthew Bohman
“With two-trap sympathetic cooling by laser-cooled beryllium ions, the limiting temperature rapidly approaches that of the ions, in the milli-Kelvin range,” explains Bohman. “Our technique shows that you can apply the laser-physics toolkit to exotic particles like antiprotons: a good antiproton trap looks pretty different from a good laser-cooled ion trap, but if you’re able to connect them by a wire or a coil you can get the best of both worlds.”
The BASE collaboration has already measured the magnetic moment of the antiproton with a record fractional precision of 1.5 parts per billion at CERN’s antimatter factory. When deployed there, two-trap sympathetic cooling has the potential to improve the precision of the measurement by at least a factor of 20. Any statistically significant difference relative to the magnetic moment of the proton would violate CPT symmetry and signal a dramatic break with the Standard Model.
“Our vision is to continuously improve the precision of our matter-antimatter comparisons to develop a better understanding of the cosmological matter-antimatter asymmetry,” says BASE spokesperson Stefan Ulmer of RIKEN. “The newly developed technique will become a key method in these experiments, which aim at measurements of fundamental antimatter constants at the sub-parts-per-trillion level. Further developments in progress at the BASE-logic experiment in Hanover will even allow the implementation of quantum-logic metrology methods to read-out the antiproton’s spin state.”
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.