Radical changes in computing and software are required to ensure the success of the LHC and other high-energy physics experiments into the 2020s, argues a new report.

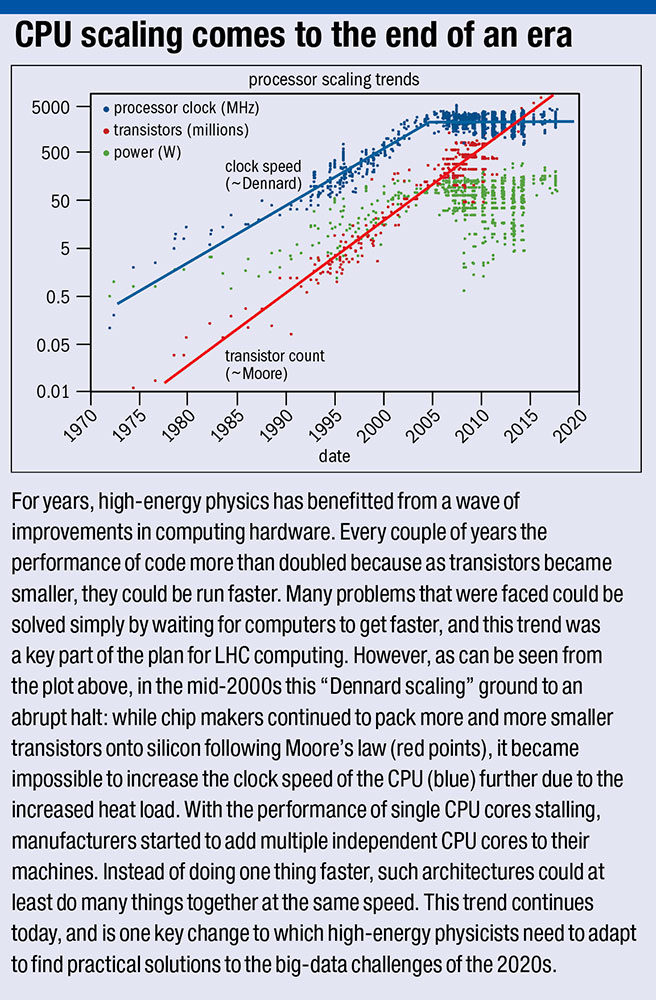
It would be impossible for anyone to conceive of carrying out a particle-physics experiment today without the use of computers and software. Since the 1960s, high-energy physicists have pioneered the use of computers for data acquisition, simulation and analysis. This hasn’t just accelerated progress in the field, but driven computing technology generally – from the development of the World Wide Web at CERN to the massive distributed resources of the Worldwide LHC Computing Grid (WLCG) that supports the LHC experiments. For many years these developments and the increasing complexity of data analysis rode a wave of hardware improvements that saw computers get faster every year. However, those blissful days of relying on Moore’s law are now well behind us (see “CPU scaling comes to the end of an era”), and this has major ramifications for our field.
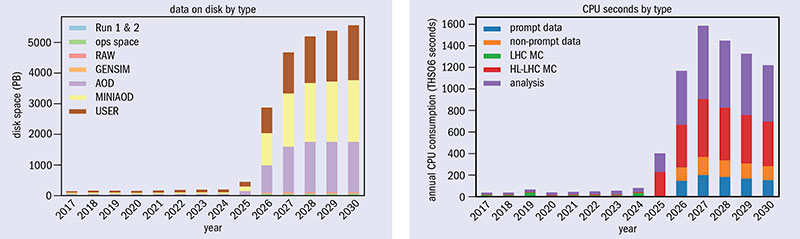
The high-luminosity upgrade of the LHC (HL-LHC), due to enter operation in the mid-2020s, will push the frontiers of accelerator and detector technology, bringing enormous challenges to software and computing (CERN Courier October 2017 p5). The scale of the HL-LHC data challenge is staggering: the machine will collect almost 25 times more data than the LHC has produced up to now, and the total LHC dataset (which already stands at almost 1 exabyte) will grow many times larger. If the LHC’s ATLAS and CMS experiments project their current computing models to Run 4 of the LHC in 2026, the CPU and disk space required will jump by between a factor of 20 to 40 (figures 1 and 2).
Even with optimistic projections of technological improvements there would be a huge shortfall in computing resources. The WLCG hardware budget is already around 100 million Swiss francs per year and, given the changing nature of computing hardware and slowing technological gains, it is out of the question to simply throw more resources at the problem and hope things will work out. A more radical approach for improvements is needed. Fortunately, this comes at a time when other fields have started to tackle data-mining problems of a comparable scale to those in high-energy physics – today’s commercial data centres crunch data at prodigious rates and exceed the size of our biggest Tier-1 WLCG centres by a large margin. Our efforts in software and computing therefore naturally fit into and can benefit from the emerging field of data science.

A new way to approach the high-energy physics (HEP) computing problem began in 2014, when the HEP Software Foundation (HSF) was founded. Its aim was to bring the HEP software community together and find common solutions to the challenges ahead, beginning with a number of workshops organised by a dedicated startup team. In the summer of 2016 the fledgling HSF body was charged by WLCG leaders to produce a roadmap for HEP software and computing. With help from a planning grant from the US National Science Foundation, at a meeting in San Diego in January 2017, the HSF brought community and non-HEP experts together to gather ideas in a world much changed from the time when the first LHC software was created. The outcome of this process was summarised in a 90-page-long community white paper released in December last year.
The report doesn’t just look at the LHC but considers common problems across HEP, including neutrino and other “intensity-frontier” experiments, Belle II at KEK, and future linear and circular colliders. In addition to improving the performance of our software and optimising the computing infrastructure itself, the report also explores new approaches that would extend our physics reach as well as ways to improve the sustainability of our software to match the multi-decade lifespan of the experiments.
Almost every aspect of HEP software and computing is presented in the white paper, detailing the R&D programmes necessary to deliver the improvements the community needs. HSF members looked at all steps from event generation and data taking up to final analysis, each of which presents specific challenges and opportunities.
Souped-up simulation
Every experiment needs to be grounded in our current knowledge of physics, which means that generating simulated physics events is essential. For much of the current HEP experiment programme it is sufficient to generate events based on leading-order calculations – a relatively modest task in terms of computing requirements. However, already at Run 2 of the LHC there is an increasing demand for next-to-leading order, or even next-to-next-to-leading order, event generators to allow more precise comparisons between experiments and the Standard Model predictions (CERN Courier April 2017 p18). These calculations are particularly challenging both in terms of the software (e.g. handling difficult integrations) and the mathematical technicalities (e.g. minimising negative event weights), which greatly increase the computational burden. Some physics analyses based on Run-2 data are limited by theoretical uncertainties and, by Run 4 in the mid-2020s, this problem will be even more widespread. Investment in technical improvements of the computation is therefore vital, in addition to progress in our underlying theoretical understanding.
Increasingly large and sophisticated detectors, and the search for rarer processes hidden amongst large backgrounds, means that particle physicists need ever-better detector simulation. The models describing the passage of particles through the detector need to be improved in many areas for high precision work at the LHC and for the neutrino programme. With simulation being such a huge consumer of resources for current experiments (often representing more than half of all computing done), it is a key area to adapt to new computing architectures.

Vectorisation, whereby processors can execute identical arithmetic instructions on multiple pieces of data, would force us to give up the simplicity of simulating each particle individually. The best way to do this is one of the most important R&D topics identified by the white paper. Another is to find ways to reduce the long simulation times required by large and complex detectors, which exacerbates the problem of creating simulated data sets with sufficiently high statistics. This requires research into generic toolkits for faster simulation. In principle, mixing and digitising the detector hits at high pile-up is a problem that is particularly suited for parallel processing on new concurrent computing architectures – but only if the rate at which data is read can be managed.
This shift to newer architectures is equally important for our software triggers and event-reconstruction code. Investing more effort in software triggers, such as those already being developed by the ALICE and LHCb experiments for LHC Run 3, will help control the data volumes and enable analyses to be undertaken directly from initial reconstruction by avoiding an independent reprocessing step. For ATLAS and CMS, the increased pile-up at high luminosity makes charged-particle tracking within a reasonable computing budget a critical challenge (figure 3). Here, as well as the considerable effort required to make our current code ready for concurrent use, research is needed into the use of new, more “parallelisable” algorithms, which maintain physics accuracy. Only these would allow us to take advantage of the parallel capabilities of modern processors, including GPUs (just like the gaming industry has done, although without the need there to treat the underlying physics with such care). The use of updated detector technology such as track triggers and timing detectors will require software developments to exploit this additional detector information.

For final data analysis, a key metric for physicists is “time to insight”, i.e. how quickly new ideas can be tested against data. Maintaining that agility will be a huge challenge given the number of events physicists have to process and the need to keep the overall data volume under control. Currently a number of data-reduction steps are used, aiming at a final dataset that can fit on a laptop but bloating the storage requirements by creating many intermediate data products. In the future, access to dedicated analysis facilities that are designed for a fast turnaround without tedious data reduction cycles may serve the community’s needs better.
This draws on trends in the data-analytics industry, where a number of products, such as Apache Spark, already offer such a data-analysis model. However, HEP data is usually more complex and highly structured, and integration between the ROOT analysis framework and new systems will require significant work. This may also lend itself better to approaches where analysts concentrate on describing what they want to achieve and a back-end engine takes care of optimising the task for the underlying hardware resource. These approaches also integrate better with data-preservation requirements, which are increasingly important for our field. Over and above preserving the underlying bits of data, a fundamental challenge is to preserve knowledge about how to use this data. Preserved knowledge can help new analysts to start their work more quickly, so there would be quite tangible immediate benefits to this approach.
A very promising general technique for adapting our current models to new hardware is machine learning, for which there exist many excellent toolkits. Machine learning has the potential to further improve the physics reach of data analysis and may also speed up and improve the accuracy of physics simulation, triggering and reconstruction. Applying machine learning is very much in vogue, and many examples of successful applications of these data-science techniques exist, but real insight is required to know where best to invest for the HEP community. For example, a deeper understanding of the impact of such black boxes and how they relate to underlying physics, with good control of systematics, is needed. It is expected that such techniques will be successful in a number of areas, but there remains much research to be done.
New challenges
Supporting the computational training phase necessary for machine learning brings a new challenge to our field. With millions of free parameters being optimised across large GPU clusters, this task is quite unlike those currently undertaken on the WLCG grid infrastructure and represents another dimension to the HL-LHC data problem. There is a need to restructure resources at facilities and to incorporate commercial and scientific clouds into the pool available for HEP computing. In some regions high-performance computing facilities will also play a major role, but these facilities are usually not suitable for current HEP workflows and will need more consistent interfaces as well as the evolution of computing systems and the software itself. Optimising storage resources into “data lakes”, where a small number of sites act as data silos that stream data to compute resources, could be more effective than our current approaches. This will require enhanced delivery of data over the network to which our computing and software systems will need to adapt. A new generation of managed networks, where dedicated connections between sites can be controlled dynamically, will play a major role.
The many challenges faced by the HEP software and computing community over the coming decade are wide ranging and hard. They require new investment in critical areas and a commitment to solving problems in common between us, and demand that a new generation of physicists is trained with updated computing skills. We cannot afford a “business as usual” approach to solving these problems, nor will hardware improvements come to our rescue, so software upgrades need urgent attention.
The recently completed roadmap for software and computing R&D is a unique document because it addresses the problems that our whole community faces in a way that was never done before. Progress in other fields gives us a chance to learn from and collaborate with other scientific communities and even commercial partners. The strengthening of links, across experiments and in different regions, that the HEP Software Foundation has helped to produce, puts us in a good position to move forward with a common R&D programme that will be essential for the continued success of high-energy physics.
Further reading
HEP Software Foundation 2017 arXiv:1712.06982.