Complex collision events challenge computing requirements.
Résumé
L’informatique du CERN prête à relever les défis de l’Exploitation 2 du LHC
Pour l’Exploitation 2, le LHC va continuer à ouvrir la voie à de nouvelles découvertes en fournissant aux expériences jusqu’à un milliard de collisions par seconde. À plus haute énergie et intensité, les collisions sont plus complexes à reconstruire et analyser ; les besoins en capacité de calcul sont par conséquent plus élevés. La deuxième période d’exploitation doit fournir deux fois plus de données que la première, soit environ 50 Po par an. Le moment est donc propice pour faire le point sur l’informatique du LHC afin de voir ce qui a été fait durant le premier long arrêt (LS1) en prévision de l’augmentation du taux de collision et de la luminosité lors de la deuxième période d’exploitation, ce qu’il est possible de réaliser aujourd’hui, et ce qui est prévu pour l’avenir.

Image credit: Roger Claus, CERN.
2015 saw the start of Run 2 for the LHC, where the machine reached a proton–proton collision energy of 13 TeV – the highest ever reached by a particle accelerator. Beam intensity also increased and, by the end of 2015, 2240 proton bunches per beam were being collided. This year, in Run 2 the LHC will continue to open the path for new discoveries by providing up to one billion collisions per second to ATLAS and CMS. At higher energy and intensity, collision events are more complex to reconstruct and analyse, therefore computing requirements must increase accordingly. Run 2 is anticipated to yield twice the data produced in the first run, about 50 petabytes (PB) per year. So it is an opportune time to look at the LHC’s computing, to see what was achieved during Long Shutdown 1 (LS1), to keep up with the collision rate and luminosity increases of Run 2, how it is performing now and what is foreseen for the future.
LS1 upgrades and Run 2
The Worldwide LHC Computing Grid (WLCG) collaboration, the LHC experiment teams and the CERN IT department were kept busy as the accelerator complex entered LS1, not only with analysis of the large amount of data already collected at the LHC but also with preparations for the higher flow of data during Run 2. The latter entailed major upgrades of the computing infrastructure and services, lasting the entire duration of LS1.
Consolidation of the CERN data centre and inauguration of its extension in Budapest were two major milestones in the upgrade plan achieved in 2013. The main objective of the consolidation and upgrade of the Meyrin data centre was to secure critical information-technology systems. Such services can now keep running, even in the event of a major power cut affecting CERN. The consolidation also ensured important redundancy and increased the overall computing-power capacity of the IT centre from 2.9 MW to 3.5 MW. Additionally, on 13 June 2013, CERN and the Wigner Research Centre for Physics in Budapest inaugurated the Hungarian data centre, which hosts the extension of the CERN Tier-0 data centre, adding up to 2.7 MW capacity to the Meyrin-site facility. This substantially extended the capabilities of the Tier-0 activities of WLCG, which include running the first-pass event reconstruction and producing, among other things, the event-summary data for analysis.
Building a CERN private cloud (cerncourier.com/cws/article/cnl/38515) was required to remotely manage the capacity hosted at Wigner, enable efficient management of the increased computing capacity installed for Run 2, and to provide the computing infrastructure powering most of the LHC grid services. To deliver a scalable cloud operating system, CERN IT started using OpenStack. This open-source project now plays a vital role in enabling CERN to tailor its computing resources in a flexible way and has been running in production since July 2013. Multiple OpenStack clouds at CERN successfully run simulation and analysis for the CERN user community. To support the growth of capacity needed for Run 2, the compute capacity of the CERN private cloud has nearly doubled during 2015, now providing more than 150,000 computing cores. CMS, ATLAS and ALICE have also deployed OpenStack on their high-level trigger farms, providing a further 45,000 cores for use in certain conditions when the accelerator isn’t running. Through various collaborations, such as with BARC (Mumbai, India) and between CERN openlab (see the text box, overleaf) and Rackspace, CERN has contributed more than 90 improvements in the latest OpenStack release.
As surprising as it may seem, LS1 was also a very busy period with regards to storage. Both the CERN Advanced STORage manager (CASTOR) and EOS, an open-source distributed disk storage system developed at CERN and in production since 2011, went through either major migration or deployment. CASTOR relies on a tape-based back end for permanent data archiving, and LS1 offered an ideal opportunity to migrate the archived data from legacy cartridges and formats to higher-density ones. This involved migrating around 85 PB of data, and was carried out in two phases during 2014 and 2015. As an overall result, no less than 30,000 tape-cartridge slots were released to store more data. The EOS 2015 deployment brought storage at CERN to a new scale and enables the research community to make use of 100 PB of disk storage in a distributed environment using tens of thousands of heterogeneous hard drives, with minimal data movements and dynamic reconfiguration. It currently stores 45 PB of data with an installed capacity of 135 PB. Data preservation is essential, and more can be read on this aspect in “Data preservation is a journey” .

Image credit: CERN.
Databases play a significant role with regards to storage, accelerator operations and physics. A great number of upgrades were performed, both in terms of software and hardware, to rejuvenate platforms, accompany the CERN IT computing-infrastructure’s transformation and the needs of the accelerators and experiments. The control applications of the LHC migrated from a file-based archiver to a centralised infrastructure based on Oracle databases. The evolution of the database technologies deployed for WLCG database services improved the availability, performance and robustness of the replication service. New services have also been implemented. The databases for archiving the controls’ data are now able to handle, at peak, one million changes per second, compared with the previous 150,000 changes per second. This also positively impacts on the controls of the quench-protection system of the LHC magnets, which has been modernised to safely operate the machine at 13 TeV energy. These upgrades and changes, which in some cases have built on the work accomplished as part of CERN openlab projects, have a strong impact on the increasing size and scope of the databases, as can be seen in the CERN databases diagram (above right).
To optimise computing and storage resources in Run 2, the experiments have adopted new computing models. These models move away from the strict hierarchical roles of the tiered centres described in the original WLCG models, to a peer site model, and make more effective use of the capabilities of all sites. This is coupled with significant changes in data-management strategies, away from explicit placement of data sets globally to a much more dynamic system that replicates data only when necessary. Remote access to data is now also allowed under certain conditions. These “data federations”, which optimise the use of expensive disk space, are possible because of the greatly improved networking capabilities made available to WLCG over the past few years. The experiment collaborations also invested significant effort during LS1 to improve the performance and efficiency of their core software, with extensive work to validate the new software and frameworks in readiness for the expected increase in data. Thanks to those successful results, a doubling of the CPU and storage capacity was needed to manage the increased data rate and complexity of Run 2 – without such gains, a much greater capacity would have been required.
Despite the upgrades and development mentioned, additional computing resources are always needed, notably for simulations of physics events, or accelerator and detector upgrades. In recent years, volunteer computing has played an increasing role in this domain. The volunteer capacity now corresponds to about half the capacity of the CERN batch system. Since 2011, thanks to virtualisation, the use of LHC@home has been greatly extended, with about 2.7 trillion events being simulated. Following this success, ATLAS became the first experiment to join, with volunteers steadily ramping up for the last 18 months and a production rate now equivalent to that of a WLCG Tier-2 site.
In terms of network activities, LS1 gave the opportunity to perform bandwidth increases and redundancy improvements at various levels. The data-transfer rates have been increased between some of the detectors (ATLAS, ALICE) and the Meyrin data centre by a factor of two and four. A third circuit has been ordered in addition to the two dedicated and redundant 100 Gbit/s circuits that were already connecting the CERN Meyrin site and the Wigner site since 2013. The LHC Optical Private Network (LHCOPN) and the LHC Open Network Environment (LHCONE) have evolved to serve the networking requirements of the new computing models for Run 2. LHCOPN, reserved for LHC data transfers and analysis and connecting the Tier-0 and Tier-1 sites, benefitted from bandwidth increases from 10 Gbps to 20 and 40 Gbps. LHCONE has been deployed to meet the requirements of the new computing model of the LHC experiments, which demands the transfer of data among any pair of Tier-1, Tier-2 and Tier-3 sites. As of the start of Run 2, LHCONE’s traffic represents no less than one third of the European research traffic. Transatlantic connections improved steadily, with ESnet setting up three 100 Gbps links extending to CERN through Europe, replacing the five 10 Gbps links used during Run 1.
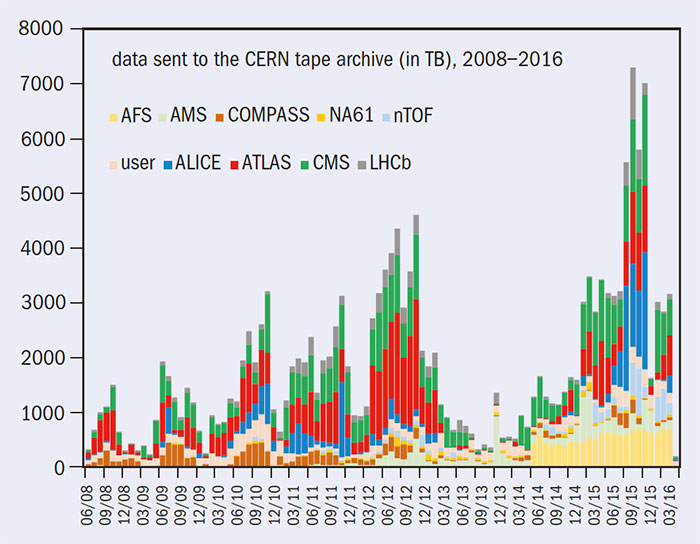
Image credit: CERN.
With the start of Run 2, supported by these upgrades and improvements of the computing infrastructure, new data-taking records were achieved: 40 PB of data were successfully written on tape at CERN in 2015; out of the 30 PB from the LHC experiments, a record-breaking 7.3 PB were collected in October; and up to 0.5 PB of data were written to tape each day during the heavy-ion run. By way of comparison, CERN’s tape-based archive system collected in the region of 70 PB of data in total during the first run of the LHC, as shown in the plot (right). In total, today, WLCG has access to some 600,000 cores and 500 PB of storage, provided by the 170 collaborating sites in 42 countries, which enabled the Grid to set a new record in October 2015 by running a total of 51.1 million jobs.
Looking into the future
With the LHC’s computing now well on track with Run 2 needs, the WLCG collaboration is looking further into the future, already focusing on the two phases of upgrades planned for the LHC. The first phase (2019–2020) will see major upgrades of ALICE and LHCb, as well as increased luminosity of the LHC. The second phase – the High Luminosity LHC project (HL-LHC), in 2024–2025 – will upgrade the LHC to a much higher luminosity and increase the precision of the substantially improved ATLAS and CMS detectors.
The requirements for data and computing will grow dramatically during this time, with rates of 500 PB/year expected for the HL-LHC. The needs for processing are expected to increase more than 10 times over and above what technology evolution will provide. As a consequence, partnerships such as those with CERN openlab and other programmes of R&D are essential to investigate how the computing models could evolve to address these needs. They will focus on applying more intelligence into filtering and selecting data as early as possible. Investigating the distributed infrastructure itself (the grid) and how one can best make use of available technologies and opportunistic resources (grid, cloud, HPC, volunteer, etc), improving software performance to optimise the overall system.
Building on many initiatives that have used large-scale commercial cloud resources for similar cases, the Helix Nebula the Science Cloud (HNSciCloud) pre-commercial procurement (PCP) project may bring interesting solutions. The project, which is led by CERN, started in January 2016, and is co-funded by the European Commission. HNSciCloud pulls together commercial cloud-service providers, publicly funded e-infrastructures and a group of 10 buyers’ in-house resources to build a hybrid cloud platform, on top of which a competitive marketplace of European cloud players can develop their own services for a wider range of users. It aims at bringing Europe’s technical development, policy and procurement activities together to remove fragmentation and maximise exploitation. The alignment of commercial and public (regional, national and European) strategies will increase the rate of innovation.
To improve software performance, the High Energy Physics (HEP) Software Foundation, a major new long-term activity, has been initiated. This seeks to address the optimal use of modern CPU architectures and encourage more commonality in key software libraries. The initiative will provide underlying support for the significant re-engineering of experiment core software that will be necessary in the coming years.
In addition, there is a great deal of interest in investigating new ways of data analysis: global queries, machine learning and many more. These are all significant and exciting challenges, but it is clear that the LHC’s computing will continue to evolve, and that in 10 years it will look very different, while still retaining the features that enable global collaboration.
| R&D collaboration with CERN openlab |
|
CERN openlab is a unique public–private partnership that has accelerated the development of cutting-edge solutions for the worldwide LHC community and wider scientific research since 2001. Through CERN openlab, CERN collaborates with leading ICT companies and research institutes. Testing in CERN’s demanding environment provides the partners with valuable feedback on their products, while allowing CERN to assess the merits of new technologies in their early stages of development for possible future use. In January 2015, CERN openlab entered its fifth three-year phase. The topics addressed in CERN openlab’s fifth phase were defined through discussion and collaborative analysis of requirements. This involved CERN openlab industrial collaborators, representatives of CERN, members of the LHC experiment collaborations, and delegates from other international research organisations. The topics include next-generation data-acquisition systems, optimised hardware- and software-based computing platforms for simulation and analysis, scalable and interoperable data storage and management, cloud-computing operations and procurement, and data-analytics platforms and applications. |