How the giant Grid underpinned the analysis of a wealth of data.
Mid-February marked the end of the first three-year run of the LHC. While the machine exceeded all expectations, delivering significantly more data to the experiments than initially foreseen, high-performance distributed computing also enabled physicists to announce on 4 July the discovery of a new particle (CERN Courier September 2012 p46). With the first run now over, it is a good time to look back at the Worldwide LHC Computing Grid to see what was initially planned, how it performed and what is foreseen for the future.
Back in the late 1990s, it was already clear that the expected amount of LHC data would far exceed the computing capacity at CERN alone. Distributed computing was the sensible choice. The first model proposed was MONARC (Models of Networked Analysis at Regional Centres for LHC Experiments), on which the experiments originally based their computing models (CERN Courier June 2000 p17). In September 2001, CERN Council approved the first phase of the LHC Computing Grid project, led by Les Robertson of CERN’s IT department (CERN Courier November 2001 p5). From 2002 to 2005, staff at CERN and collaborating institutes around the world developed prototype equipment and techniques. From 2006, the LHC Computing Grid became the Worldwide LHC Computing Grid (WLCG) as global computing centres became connected to CERN to help store data and provide computing power.
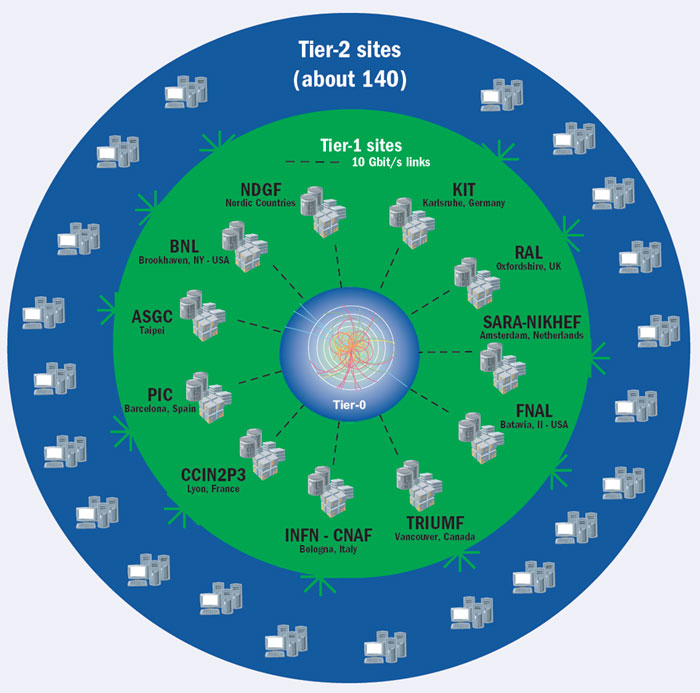
WLCG uses a tier structure with the CERN data centre as Tier-0 (figure 1). CERN sends out data to each of the 11 major data centres around the world that form the first level, or Tier-1, via optical-fibre links working at multiples of 10 Gbit/s. Each Tier-1 site is then linked to a number of Tier-2 sites, usually located in the same geographical region. Computing resources are supported by the national funding agencies of the countries where each tier is located.
Exceeding expectations
Before the LHC run began, the experiment collaborations had high expectations for the Grid. Distributed computing was the only way that they could store, process and analyse the data – both simulated and real. But, equally, there was some hesitation: the scale of the data processing was unprecedented and it was the first time that analysis had been distributed in this way, dependent on work done at so many different places and funded by so many sources.
There was caution on the computing side too; concerns about network reliability led to built-in complexities such as database replication. As it turned out, the network performed much better than expected. Networking in general saw a big improvement, with connections of 10 Gbit/s being more or less standard to the many university departments where the tiers are housed. Greater reliability, greater bandwidth and greater performance led to increased confidence. The initial complexities and the need for replication of databases reduced, and over time the Grid saw increased simplicity, with a greater reliance on central services run at CERN.
A wealth of data
Network improvements, coupled with the reduced costs of computing hardware meant that more resources could be provided. Improved performance allowed the physics to evolve as the LHC experiments increased their trigger rates to explore more regions than initially foreseen, thus increasing the instantaneous data. LHCb now writes as much data as had been initially estimated for ATLAS and CMS. In 2010, the LHC produced its nominal 15 petabytes (PB) of data a year. Since then, it has increased to 23 PB in 2011 and 27 PB in 2012. LHC data contributed about 70 PB to the recent milestone of 100 PB of CERN data storage (see p6).
In ATLAS and CMS, at least one collision took place every 50 ns i.e. with a frequency of 20 MHz. The ATLAS trigger output-rate increased over the years to up to 400 Hz of output into the main physics streams in 2012, giving more than 5.5 × 109 recorded physics collisions. CMS collected more than 1010 collision events after the start of the run and reconstructed more than 2 × 1010 simulated crossings.
For ALICE, the most important periods of data-taking were the heavy-ion (PbPb) periods – about 40 days in 2010 and 2011. The collaboration collected some 200 million PbPb events with various trigger set-ups. These periods produced the bulk of the data volume in ALICE and their reconstruction and analysis required the biggest amount of CPU resources. In addition, the ALICE detector operated during the proton–proton periods and collected reference data for comparison with the heavy-ion data. In 2013, just before the long shutdown, ALICE collected asymmetrical proton–lead collisions with an interaction versus trigger rate of 10%. In total, from 2010, ALICE accumulated about 8 PB of raw data. Add to that the reconstruction, Monte Carlo simulations and analysis results, and the total data volume grows to about 20 PB.
In LHCb, the trigger reduces 20 million collisions a second to 5000 events written to tape each second. The experiment produces about 350 MB of raw data per second of LHC running, with the total raw data recorded since the start of LHC at about 3 PB. The total amount of data stored by LHCb is 20 PB, of which about 8 PB are on disk. Simulated data accounts for about 20% of the total. On average, about one tenth of the jobs running concurrently on the WLCG come from LHCb.
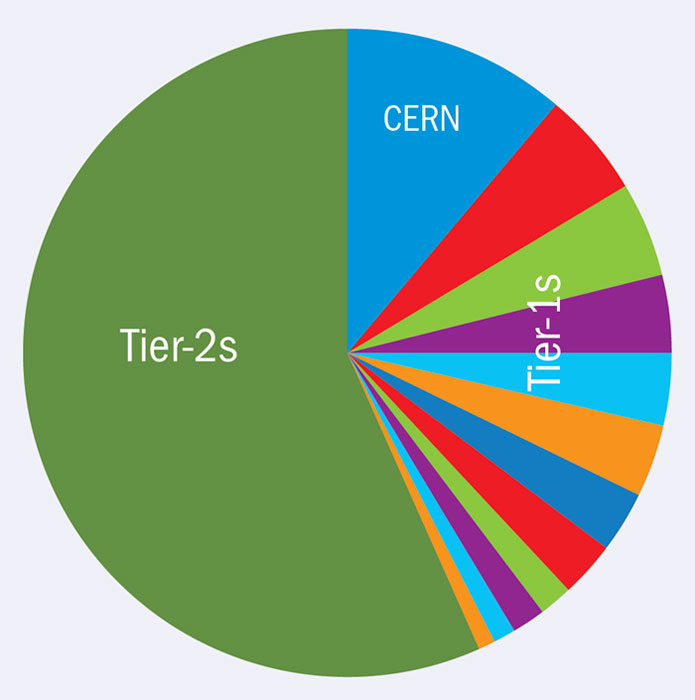
The WLCG gives access to vast distributed resources across the globe in Tier-1 and Tier-2 sites, as well as to additional voluntary resources from interested institutions, ensuring built-in resilience because the analysis is not performed in a single data centre and hence is not dependent on that centre. It also makes the LHC data available worldwide at the same time.
As time has gone on, the Tier-2 sites have been used far more than foreseen (figure 2). Originally thought to be just for analysis and Monte Carlo simulations, the sites can now do much more with more resources and networking than anticipated. They currently contribute to data reprocessing, normally run at Tier-1 sites, and have enabled the Grid to absorb peak loads that have arisen when processing real data as a result of the extension of the LHC run and the higher-than-expected data collection rates. Because the capacity available at Tier-0 and Tier-1 was insufficient to process new data and reprocess earlier data simultaneously, the reprocessing activity was largely done on Tier-2s. Without them it would not have been possible to have the complete 2012 data set reprocessed in time for analyses targeting the winter conferences in early 2013.
The challenges for the Grid were three-fold. The main one was to understand how best to manage the LHC data and use the Grid’s heterogeneous environment in a way that physicists could concern themselves with analysis without needing to know where their data were. A distributed system is more complex and demanding to master than the usual batch-processing farms, so the physicists required continuous education on how to use the system. The Grid needs to be fully operational at all times (24/7, 365 days/year) and should “never sleep” (figure 3), meaning that important upgrades of the Grid middleware in all data centres must be done on a regular basis. For the latter, the success can be attributed in part to the excellent quality of the middleware itself (supplied by various common projects, such as WLCG/EGEE/EMI in Europe and OSG in the US, see box) and to the administrators of the computing centres, who keep the computing fabric running continuously.
Requirements for the future
With CERN now entering its first long shutdown (LS1), the physicists previously on shift in the control rooms are turning to analysis of the data. Hence LS1 will not be a period of “pause” for the Grid. In addition to analysis, the computing infrastructure will undergo a continual process of upgrades and improvements.
The computing requirements of ALICE, ATLAS, CMS and LHCb are expected to evolve and increase in conjunction with the experiments’ physics programmes and the improved precision of the detectors’ measurements. The ALICE collaboration will re-calibrate, re-process and re-analyse the data collected from 2010 until 2013 during LS1. After the shutdown, the Grid capacity (CPU and storage) will be about 30% more than that currently installed, which will allow the experiment to resume data-taking and immediate data processing at the higher LHC energy. The ATLAS collaboration has an ambitious plan to improve its software and computing performance further during LS1 to moderate the increase in hardware needs. They nonetheless expect a substantial increase in their computing needs compared with what was pledged for 2012. The CMS collaboration expects the trigger rate – and subsequently the processing and analysis challenges – to continue to grow with the higher energy and luminosity after LS1. LHCb’s broader scope to include charm physics may increase the experiment’s data rate by a factor of about two after LS1, which would require more storage on the Grid and more CPU power. The collaboration also plans to make much more use of Tier-2 sites for data processing than was the case up until now.
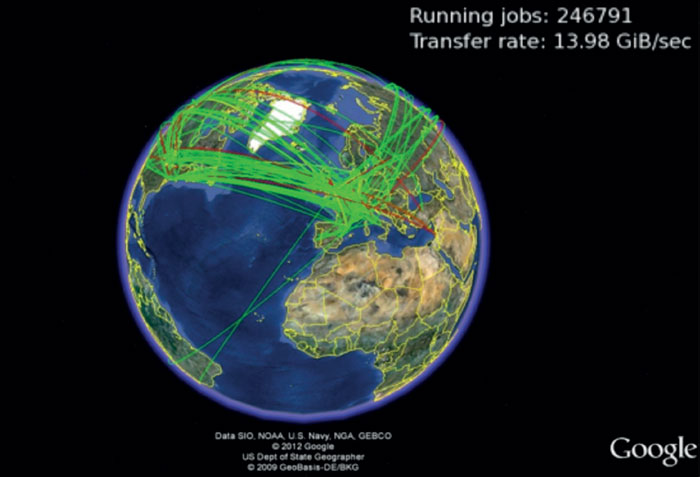
Image credit: Data SIO, NOAA, US Navy, NGA, GEBCO, Google, US Dept. of State Geographer, GeoBasis, DE/BKG.
For the Grid itself, the aim is to make it simpler and more integrated, with work now underway to extend CERN’s Tier-0 data centre, using resources at CERN and the Wigner Research Centre in Budapest (CERN Courier June 2012 p9). Equipment is already being installed and should be fully operational in 2013.
Future challenges and requirements are the result of great successes. Grid performance has been excellent and all of the experiments have not only been good at recording data, but have also found that their detectors could even do more. This has led to the experiment collaborations wanting to capitalize on this potential. With a wealth of data, they can be thankful for the worldwide computer, showing global collaboration at its best.
| Worldwide LHC Computing Grid in numbers |
| • About 10,000 physicists use it
• On average well in excess of 250,000 jobs run concurrently on the Grid • 30 million jobs ran in January 2013 • 260,000 available processing cores • 180 PB disk storage available worldwide • 15% of the computing resources are at CERN • 10 Gbit/s optical-fibre links connect CERN to each of the 11 Tier-1 institutes • There are now more than 70 PB of stored data at CERN from the LHC |
| Beyond particle physics |
| Throughout its lifetime, WLCG has worked closely with Grid projects co-funded by the European Commission, such as EGEE (Enabling Grids for E-sciencE), EGI (European Grid Infrastructure) and EMI (European Middleware Initiative), or funded by the US National Science Foundation and Department of Energy, such as OSG (Open Science Grid). These projects have provided operational and developmental support and enabled wider scientific communities to use Grid computing, from biologists who simulate millions of molecular drug candidates to find out how they interact with specific proteins, to Earth-scientists who model the future of the planet’s climate.
|