
A report on the latest workshop on the use of statistics in particle physics.
With the LHC due to start running next year, the PHYSTAT-LHC workshop on Statistical Issues for LHC Physics provided a timely opportunity to discuss the statistical techniques to be used in the various LHC analyses. The meeting, held at CERN on 27–29 June, attracted more than 200 participants, almost entirely from the LHC experiments.
The PHYSTAT series of meetings began at CERN in January 2000 and has addressed various statistical topics that arise in the analysis of particle-physics experiments. The meetings at CERN and Fermilab in 2000 were devoted to the subject of upper limits, which are relevant when an experiment fails to observe an effect and the team attempts to quantify the maximum size the effect could have been, given that no signal was observed. By contrast, with exciting results expected at the LHC, the recent meeting at CERN focused on statistical problems associated with quantifying claims of discoveries.

Image credit: Jogesh Babu.
The invited statisticians, though few in number, were all-important participants – a tradition started at the SLAC meeting in 2003. Sir David Cox of Oxford, Jim Berger of Duke University and the Statistical and Applied Mathematical Sciences Institute, and Nancy Reid of Toronto University all spoke at the meeting, and Radford Neal, also from Toronto, gave his talk remotely. All of these experts are veterans of previous PHYSTAT meetings and are familiar with the language of particle physics. The meeting was also an opportunity for statisticians to visit the ATLAS detector and understand better why particle physicists are so keen to extract the maximum possible information from their data – we devote much time and effort to building and running our detectors and accelerators.
The presence of statisticians greatly enhanced the meeting, not only because their talks were relevant, but also because they were available for informal discussions and patiently explained statistical techniques. They gently pointed out that some of the “discoveries” of statistical procedures by particle physicists were merely “re-inventions of the wheel” and that some of our wheels resemble “triangles”, instead of the already familiar “circular” ones.
The meeting commenced with Cox’s keynote address, The Previous 50 Years of Statistics: What Might Be Relevant For Particle Physics. In particular, he discussed multiple testing and the false discovery rate – particularly relevant in general-purpose searches, where there are many possibilities for a statistical fluctuation to be confused with a discovery of some exciting new physics. Cox reminded the audience that it is more important to ask the correct question than to perform a complicated analysis, and that when combining data, first to check that they are not inconsistent.
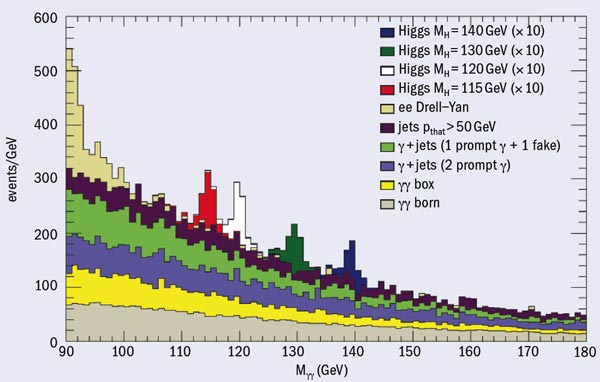
One approach to searching for signs of new physics is to look for deviations from the Standard Model. This is usually quantified by calculating the p-value, which gives the probability – assuming the Standard Model is true – of finding data at least as discrepant as that observed. Thus a small p-value implies an inconsistency between the data and the Standard Model prediction. This approach is useful in looking for any sort of discrepancy. The alternative is to compare the predictions of the Standard Model with some specific alternative, such as a particular version of supersymmetry. This is a more powerful way of looking for this particular form of new physics, but is likely to be insensitive to other possibilities.
Luc Demortier of Rockefeller University gave an introduction to the subject of p-values, and went on to discuss ways of incorporating systematic uncertainties in their calculation. He also mentioned that, in fitting a mass spectrum to a background-only hypothesis and to a background plus a 3-parameter peak, it is a common misconception that in the absence of any signal, the difference in χ2 of the two fits behaves as a χ2 with 3 degrees of freedom. The talk by Kyle Cranmer of Brookhaven National Laboratory dealt with the practical issues of looking for discoveries at the LHC. He too described various methods of incorporating systematics to see whether a claim of 5 σ statistical significance really does correspond to such a low probability. The contributed talk by Jordan Tucker from University of California, Los Angeles, (UCLA) also explored this.
While the LHC is being completed, the CDF and DØ experiments are taking data and analysing it at the Fermilab collider, which currently provides the highest accelerator energies. Fermilab’s Wade Fisher summarized the experience gained from searches for new phenomena. Later, speakers from the major LHC experiments discussed their “statistical wish-lists” – topics on which they would like advice from statistics experts. Jouri Belikov of CERN spoke for the ALICE experiment, Yuehong Xie of Edinburgh University for LHCb and Eilam Gross of the Weizmann Institute for ATLAS and CMS. It was particularly pleasing to see the co-operation between the big general-purpose experiments ATLAS and CMS on this and other statistical issues. The Statistics Committees of both work in co-operation and both experiments will use the statistical tools that are being developed (see below). Furthermore, it will be desirable to avoid the situation where experiments make claims of different significance for their potential discoveries, not because their data are substantially different, but simply because they are not using comparable statistical techniques. Perhaps PHYSTAT can claim a little of the credit for encouraging this collaboration.
When making predictions for the expected rate at which any particle will be produced at the LHC, it is crucial to know the way that the momentum of a fast-moving proton is shared among its constituent quarks and gluons (known collectively as partons). This is because the fundamental interaction in which new particles are produced is between partons in the colliding protons. This information is quantified in the parton distribution functions (PDFs), which are determined from a host of particle-physics data. Robert Thorne of University College London, who has been active in determining PDFs, explained the uncertainties associated with these distributions and the effect that they have on the predictions. He stressed that other effects, such as higher-order corrections, also resulted in uncertainties in the predicted rates.
Statisticians have invested much effort on “experimental design”. A typical example might be how to plan a series of tests investigating the various factors that might affect the efficiency of some production process; the aim would be to determine which factors are the most critical and to find their optimal settings. One application for particle physicists is to decide how to set the values of parameters associated with systematic effects in Monte Carlo simulations; the aim here is to achieve the best accuracy of the estimate of systematic effects with a minimum of computing. Since a vast amount of computing time is used for these calculations, the potential savings could be very useful. The talks by statisticians Reid and Neal, and by physicist Jim Linnemann of Michigan State University, addressed this important topic. Plans are underway to set up a working group to look into this further, with the aim of producing recommendations on this issue.

Two very different approaches to statistics are provided by the Bayesian and frequentist approaches (see box). Berger gave a summary of the way in which the Bayesian method could be helpful. One particular case that he discussed was model selection, where Bayesianism provides an easy recipe for using data to choose between two or more competing theories.
With the required software for statistical analyses becoming increasingly complicated, Wouter Verkerke from NIKHEF gave an overview of what is currently available. A more specific talk by Lorenzo Moneta of CERN described the statistical tools within the widely used ROOT package developed by CERN’s René Brun and his team. An important topic in almost any analysis in particle physics is the use of multivariate techniques for separating the wanted signal from undesirable background. There is a vast array of techniques for doing this, ranging from simple cuts via various forms of discriminant analysis to neural networks, support vector machines and so on. Two largely complementary packages are the Toolkit for Multivariate Data Analysis and StatPatternRecognition. These implement a variety of methods that facilitate comparison of performance, and were described by Frederik Tegenfeldt of Iowa State University and Ilya Narsky of California Institute of Technology, respectively. It was reassuring to see such a range of software available for general use by all experiments.
Although the theme of the meeting was the exciting discovery possibilities at the LHC, Joel Heinrich of University of Pennsylvania returned to the theme of upper limits. At the 2006 meeting in Banff, Heinrich had set up what became known as the “Banff challenge”. This consisted of providing data with which anyone could try out their favourite method for setting limits. The problem included some systematic effects, such as background uncertainties, which were constrained by subsidiary measurements. Several groups took up the challenge and provided their upper limit values to Heinrich. He then extracted performance figures for the various methods. It seemed that the “profile likelihood” did well. A talk by Paul Baines of Harvard University described the “matching prior” Bayesian approach.
Unlike the talks that sometimes conclude meetings, the summary talk by Bob Cousins of UCLA was really a review of the talks presented at the workshop. He had put an enormous amount of work into reading through all of the available presentations and then giving his own comments on them, usefully putting the talks of this workshop in the context of those presented at earlier PHYSTAT meetings.
Overall, the quality of the invited talks at PHYSTAT-LHC was impressive. Speakers went to great lengths to make their talks readily intelligible: physicists concentrated on identifying statistical issues that need clarification; statisticians presented ideas that can lead to improved analysis. There was also plenty of vigorous discussion between sessions, leading to the feeling that meetings such as these really do lead to an enhanced understanding of statistical issues by the particle-physics community. Gross coined the word “phystatistician” for particle physicists who could explain the difference between the probability of A, given that B had occurred, compared with the probability of B, given that A had occurred. When the LHC starts up in 2008, it will be time to put all of this into practice. The International Committee for PHYSTAT concluded that the workshop was successful enough that it was worth considering a further meeting at CERN in summer 2009, when real LHC data should be available.



